
RTMP
什么是 RTMP
一种应用层的实时信息传输协议,对低延时和音视频同步有良好的支持。解决多媒体数据传输流的分包和多路复用的问题
- message 消息:将数据封装成消息,是 RTMP 协议中的基本数据单元
- chunk 块:将消息分包成更小的块,基于TCP网络传输
RTMP 设计思想
分包:可以将大的消息数据分包成小的块通过网络来进行传输,是降低延时的关键多路复用:音频、视频数据就能够合到一个传输流(块流)中进行同步传输,是音视频同步的关键消息分优先级设计:优先级:控制消息 > 音频消息 > 视频消息,当网络传输能力受限时优先传输高优先级数据。要使优先级能够有效执行,分块也很关键:将大消息切割成小块,可以避免大的低优先级的消息(视频消息)堵塞了发送缓冲而延误高优先级的消息(音频、控制消息)块大小协商:充分考虑流媒体服务器、带宽、客户端的情况,通过块大小协商动态的适应环境Header压缩优化:块 Header 最大 12 字节,最小可以压缩到 1 字节,节省带宽
创建流的过程
1.建立TCP连接
2.RTMP握手
- 客户端发送 C0 表示版本号、紧接着发送 C1 表示时间戳
- 服务器收到 C0 的时候,返回 S0 表明自己的版本号(版本不匹配则断开),然后直接发送时间戳 S1
- 客户端收到 S1 的时候,发一个知道了对方时间戳的 ACK C2,同理服务器收到 C1 的时候发 S2
3.建立RTMP连接
- 客户端发送connect命令,请求与一个服务应用实例建立连接
- 服务器接收到连接命令消息后,发送确认窗口大小协议消息,同时连接应用程序
- 服务器发送设置带宽协议消息到客户端
- 客户端处理设置带宽协议消息后,发送确认窗口大小协议消息到服务器端
- 服务器发送Stream Begin
- 服务器发送命令消息中的result,通知客户端连接的状态
4.创建RTMP流
- 客户端发送 createStream 命令
- 服务器发送命令消息中的result,通知客户端流的状态。
推流
- 客户端发送publish命令到服务器,请求创建绑定推流
- 服务端返回onStatus告知结果
- 客户端向服务器设置**媒体元数据 **
- 服务端直接将metaData转发给订阅者,以便解码器初始化
- 服务端解析metaData,设置解码器
- 客户端向服务器推送媒体数据
拉流
- 客户端发送 play 命令到服务器,指定播放哪个频道
- 服务器发送设置块大小协议消息
- 服务器发送streambegin告知客户端流ID
- 服务器发送onStatus告知客户端成功
- 此后服务器发送音视频数据
RTMP Message Header
注意:消息需要分块发送。消息的类型只是消息本身格式的设定,和分块传输过程是不同的概念。应该把消息格式理解为消息的信息排列样式;把传输过程理解为物理上发送数据的方案。
RTMP 消息的头(而非 Message Header)是会被切割到 Chunk 里传输的。不过因为和 Chunk Header 内容重复,实际的实现上也可以不考虑这个(得约定好)
- MessageType
1B:类型 ID 1 - 6 被保留用于协议控制消息 - MessageLength
3B:表示有效负载的字节数,大端格式 - Timestamp
4B:包含了当前消息的 timestamp,大端格式 - StreamID
3B:消息归属消息流 ID 标志位,大端格式
RTMP Chunk
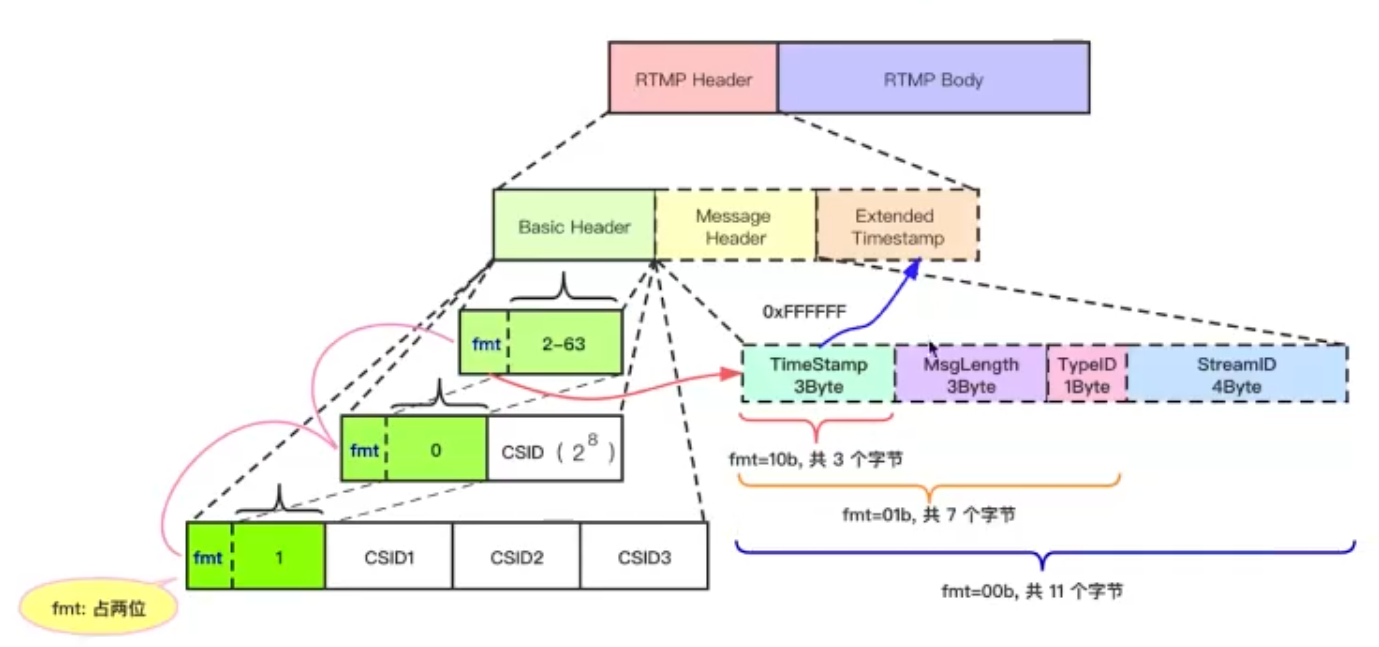
Basic Header:存放fmt和CSID,长度取决第一个字节的后6位
- 0:Header占2字节,CSID从64开始,范围 $2^8$
- 1:Header占4字节,CSID从64+$2^8$开始,范围$2^{24}$
- 2-63:Header占1字节,后6位本身即为CSID,范围2-63
Message Header:长度可变,取决于fmt
StreamID
4B:同一个流中的消息(除了第一个),可省略MessageType
1B:同一个消息拆分成的chunk,消息类型相同可省略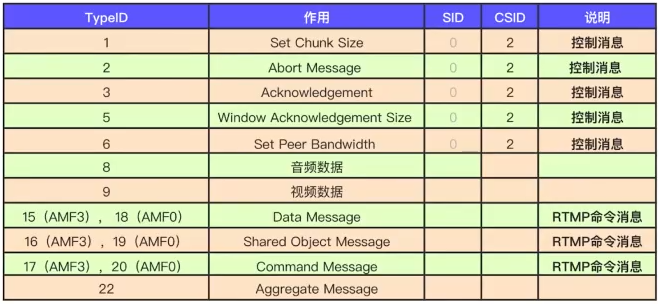
MessageLength
3B:同一个消息中chunk大小固定,可省略TimeStamp
3B:前三个都相同且chunk由同一个Message切割而来,则时间戳相同,可省略
Extended Time Stamp:可选,TimeStamp为0xFFFFFF时采用扩展时间戳
RTP/RTCP与RTSP
流式传输
包括顺序流式传输和实时流式传输。直播场景中使用两者均可,但实时流式传输的延迟应当更低。
RTP 实时传输协议
RTP为IP网络上多媒体数据提供端到端的实时传输服务。为端到端的实时传输提供时间信息和流同步,但并不保证服务质量,服务质量(乱序、流量控制)由RTCP来提供
- RTP被划分在传输层,它建立在UDP上。载荷按IP-UDP-RTP的结构进行封装,其中RTP头12B
- 整个RTP协议由两个密切相关的部分组成:RTP数据协议和RTP控制协议(即RTCP)
RTCP 实时传输控制协议
RTCP同样是基于UDP的,但是每一个RTCP包都只包含一些控制信息,因而会很短,可以把多个RTCP分组封装在一个UDP包中。RTCP的原理是向会话中的所有成员周期性地发送控制包,应用程序通过接收这些控制数据包,从中获取会话参与者的相关资料,以及网络状况、丢包率等反馈信息,从而控制服务质量或者诊断网络状况。但当有许多用户一起加入会话进程的时候,由于每个参与者都周期发送RTCP信息包,导致RTCP包泛滥
RTCP协议的不同数据包:
- SR(Sender Report):类型200,发送端报告,用来使发送端以多播方式向所有接收端报告发送情况。发送端是指发出RTP数据报的终端,可以同时作为接收端。
- RR(Receiver Report):类型201,接收端报告,接收端是指仅接收但不发送RTP数据报的终端
- SDES:类型202,源描述,用于报告和站点相关的信息。
- BYE:类型203,是站点离开系统的报告,表示结束
- APP:类型204,由应用程序自己定义,解决了RTCP的扩展性问题
RTSP 实时流协议
RTSP是一个基于文本的多媒体播放控制协议,属于应用层。RTSP主要用来控制具有实时特性的数据的发送,但其本身并不用于传送流媒体数据,而必须依赖下层传输协议(如RTP/RTCP)所提供的服务来完成流媒体数据的传送。RTSP负责定义具体的控制信息、操作方法、状态码,以及描述与RTP之间的交互操作。
- RTSP的请求主要有DESCRIBE,SETUP,PLAY,PAUSE,TEARDOWN,OPTIONS等
- RTSP控制的流媒体一般传输TS、MP4之类的格式
RTSP的工作流程
- 首先,客户端连接到流服务器并发送 DESCRIBE 命令
- 流服务器返回一个SDP描述,包括流数量、媒体类型等
- 客户端再分析该SDP描述,并为会话中的每一个流发送一个 SETUP 命令,告诉服务器客户端接收媒体数据的端口,流媒体连接建立完成
- 客户端发送 PLAY 命令,服务器就开始在UDP上传送媒体流 (RTP包)。在播放过程中客户端还可以向服务器发送命令来控制快进、快退和暂停等
- 最后,客户端可发送 TERADOWN 命令来结束流媒体会话
MP4
在 MP4 文件中,Chunk 是最小的基本单位,是为了优化数据的 I/O 读取效率,媒体数据 -> chunk -> sample -> 帧(默认1个)
Box结构
- box header:box的元数据
- type:4B,box类型,包括 预定义类型、自定义扩展类型
- size:4B,整个box的字节数,为0时大小由8B的largesize确定,为1时表示是最后一个box
- box body:数据部分存储的内容跟box类型有关,有的很简单如 ftyp,有的可能嵌套了其他box比如moov
Container box:嵌套其他box
FullBox:扩展多了 version、flags 字段
- version:1B,当前box的版本,为扩展做准备
- flags:3B,标志位,含义由具体的box自己定义
Box类型
ftyp (file type box):描述文件遵从的MP4规范与版本
- major_brand:最好基于哪种格式来解析文件,比如常见的 isom、mp41/42、avc1、qt等
- minor_version:提供 major_brand 的说明信息,比如版本号
- compatible_brands:文件兼容的brand列表
moov (movie box):媒体的metadata信息,有且仅有一个
- mvhd:mp4文件的整体信息,比如创建时间、文件时长
- trak (
Track Box):包含的轨道信息,是container box,至少包含两个box- tkhd:单个 track 的信息,如track创建时间、时长,音频音量、视频宽高
- mdia:
- mdhd (
Media Header Box) - hdlr (
Handler Reference Box):声明track的类型,以及对应的处理器 - minf (
Media Information Box): trak 中媒体数据的所有特征信息- vmhd / smhd
- stbl (
Sample Table Box):是包含媒体数据信息最多的 Box。主要包含了时间和媒体采样数据的索引表,能按照时间检索出采样数据的位置、类型(是否 I 帧)、大小、实际偏移位置- stsd (
Sample Description):音视频的编码、宽高、音量,每个sample中包含多少个帧(包含SPS 和 PPS) - stco (
Chunk Offset):chunk索引表,chunk在文件中的偏移 - stsc (
Sample To Chunk):包含 Sample 和 Chunk 的映射关系,即每个chunk中包含几个sample,用来找到包含 sample 的 chunk - stsz (
Sample Size):每个sample的大小,AVPacket的size大小 - stts (
Decoding Time to Sample):每个sample的时长( 相邻两帧的解码间隔) - stss (
Sync Sample):哪些sample是关键帧 - ctts (
Composition Time to Sample): 时间补偿,用来计算出 pts,因为mp4 是按解码顺序存储,packet 按 dts 递增。通常用于B帧场景
- stsd (
- mdhd (
mdat (Media Data Box):存放实际的媒体数据,这里数据是没有结构的,依赖于moov中的信息索引
Moov和Mdat的前后
- moov 在 mdat 后面:修改moov中的用户自定义信息时,不会影响 Chunk Offset,无需更新 stco ,编辑效率较高。但从网络播放 MP4 时就需较长时间,直到播放器获取到 moov 数据后才能初始化解码器并播放
- moov 在 mdat 前面:则与上述情况相反,这时候从网络读取和播放 MP4 文件时,就可以较快获取到 moov 的数据并开始播放。所以对于通过网络播放 MP4 视频的场景,都建议将视频处理为 moov 前置。
Seek操作原理
- sample = 秒数 * 帧率
- stsc根据sample找到chunk,以及该chunk中前面sample的数量
- stco找到chunk偏移位置
- stsz确定每个sample大小,求和即为字节数
FLV
FLV是基于流式的文件存储结构,可以随时将音视频数据写入文件末尾,且文件头不会因文件数据的大小而变化,所以不管是在录制时,还是进行回放时,FLV 相较于 MP4 等多媒体格式都更有优势
与RTMP对比发现:FLV 文件就是由 “FLV Header + RTMP 数据” 构成的
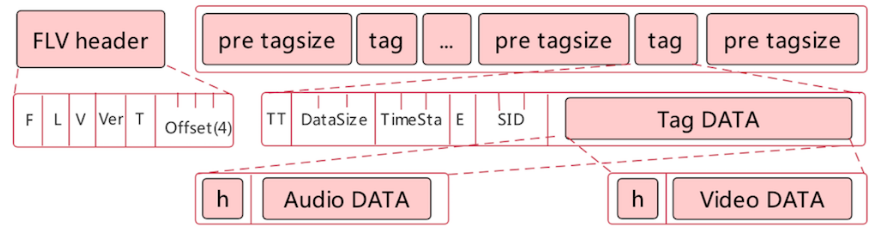
格式
FLV Header
- T:Type标识占1字节,其中两位表明是否包含音频或视频
- Offset:Header长度,固定为9B
FLV Body
- Pre TagSize:占4字节,表示前一个Tag大小
- Tag Header:同RTMP Header
- TagType
1B:类型音频、视频、脚本数据 - DataSize
3B:数据长度 - Timestamp和扩展Timestamp
4B:数据生成时间戳 - StreamID
3B:总为0
- TagType
- Tag Data:存放
AudioHeader + AudioData或VideoHeader + VideoData
TagData
- Script Tags
存放FLV视频和音频的元信息(onMetadata),是第一个Tag,且仅有一个 - Audio Tags
在 FLV 中一般会用第一个 Audio Tag 来封装 AudioSpecificConfig。如果音频使用 AAC 编码格式,那么这个 Tag 就是 AAC 音频同步包 - Video Tags
在 FLV 中一般会用第一个 Video Tag 来封装 AVCDecoderConfigurationRecord。如果视频使用 AVC 编码格式,那么这个 Tag 就是 AVC 视频同步包。它记录了 AVC 解码相关的 sps 和 pps 信息,解码器在解码前要先获取的 sps 和 pps ,在做 seek 等操作引起解码器重启时,也需再传一遍 sps 和 pps
AAC编码
ADTS格式
每一帧的ADTS的头文件都包含音频的采样率,声道,帧长度等信息
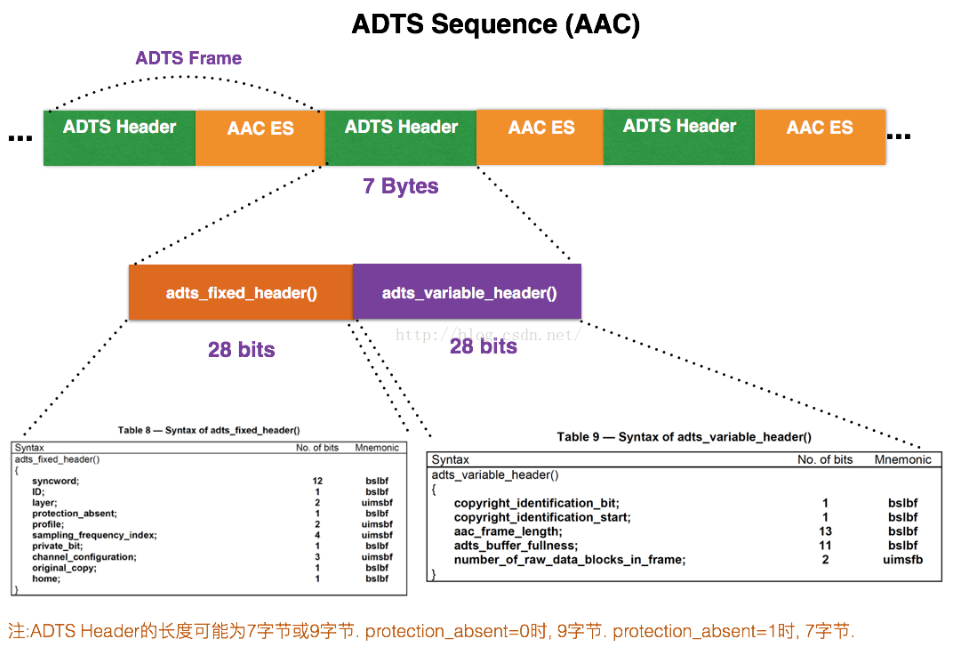
- syncword :固定
0xFFF,代表一个ADTS帧的开始 - ID:MPEG版本: MPEG-4为0,MPEG-2为1
- Layer:固定
0x00 - protection_absent:需要CRC校验为0(header length=9B),不需要为1(7B),
- profile:表示使用哪个级别的AAC
- sampling_frequency_index:采样率的下标,如44.1k对应
0x4 - channel_configuration:声道数,如2表示立体声双声道
- aac_frame_length:ADTS帧的长度 = (protection_absent == 1 ? 7 : 9) + size(AACFrame)
- adts_buffer_fullness:
0x7FF说明是码率可变的码流。 - number_of_raw_data_blocks_in_frame:表示ADTS帧中有
k+1个AAC原始帧 - AAC首部分析网站
JPEG编码
块划分:源图像中每点的 3个分量是交替出现的,先要分开存放到 3 张表中去。按8x8大小划分块,不足则填充
DCT变换:先将图像分层N*N的像素块,再针对每个像素块逐一DCT操作。编码时正向DCT变换,解码时反向
Zigzag 扫描排序:从左上角Z形扫描并保存DCT系数
量化:量化阶段需要两个 8*8 量化表,分别处理亮度和色度的频率系数,将频率系数除以量化矩阵的值之后取整,即完成了量化过程。量化阶段之后所有数据只保留了整数近似值,会有损失。在 JPEG 算法中,由于对亮度和色度的精度要求不同,分别对亮度和色度采用不同的量化表,前者细量化,后者粗量化。
DC和AC分量编码:
DC进行DPCM差值编码,因为相邻DC系数值变化不大,取同一个图像分量中相邻DC的差值来进行编码
AC进行行程长度编码,因为系数中很多0,所以用一个数据对表示两个非零AC系数间的0个数
熵编码:
对得到的DC和AC系数的中间格式进行熵编码,JPEG标准规定了两种方式:Huffman编码和算术编码,JPEG基本系统规定采用Huffman编码
Huffman编码:对出现概率大的字符分配字符长度较短的二进制编码,对出现概率小的字符分配字符长度较长的二进制编码,从而使得字符的平均编码长度最短。具体Huffman编码采用查表的方式高效地完成,需要4张Huffman编码表:DC系数&AC系数、亮度&色度
H264 /AVC
en.wikipedia.org/wiki/Advanced_Video_Coding
H264码流结构
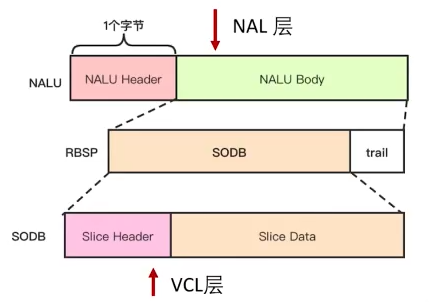
VCL和NAL
VCL:视频编码层,H264编码的核心,负责将视频数据编码压缩、切分
VCL层是对核心算法引擎,宏块及片的语法级别的定义,输出编码完的数据 SODB
NAL:网络抽象层,负责将VCL的数据组织打包,解决丢包、乱序
NAL层定义片级以上的语法级别(如SPS和PS,针对网络传输),同时支持独立片解码,保证起始码唯一
分层结构
封闭式GOP:指每一个GOP都以IDR开始,各个GOP之间独立地编解码
开放式GOP:指第一个GOP中的第一个帧内编码图像是IDR,后续GOP中的第一个帧内编码图像为non-IDR图像,因此后面GOP中的帧间编码图像可以用前一个GOP中的已编码图像做参考图像
GOP值大的好处:
- 在码率不变的前提下,GOP值越大,P、B帧的数量会越多,画面细节更多,图像质量越高;
GOP值大的局限:
- 场景切换时,编码器会自动强制插入一个I帧,此时实际的GOP值被缩短了
- 当I帧的图像质量差时会影响到后续P、B帧的质量,直到下一个GOP开始才有可能得以恢复
- 过多的P、B帧会影响编码效率,使编码效率降低
- 过长的GOP还会影响Seek操作的响应速度,解码某一个P或B帧时,需要先解码得到本GOP内的I帧及之前的N个预测帧才可以,GOP值越长,需要解码的预测帧就越多,seek响应的时间也越长。
五个层次:GOP -> 图像 -> Slice -> 宏块 ->子块
- 封闭式GOP:一组连续的画面,第一帧为IDR帧,一般由一张 I 帧和数张 B / P 帧组成
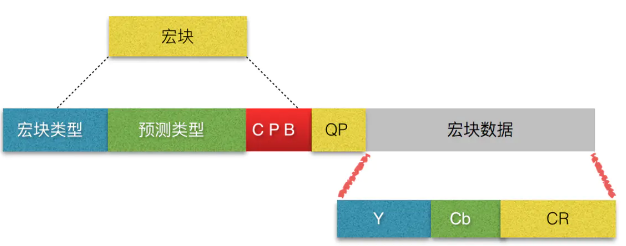
- 片 slice:宏块的载体,限制误码的扩散和传输(常一帧图片对应一个slice) ,Slice Header中包括帧类型、GOP中解码帧的序号、预测权重、滤波
- 宏块 Macroblock:宏块大小通常为16×16像素,分为I、B、P宏块;编码处理的基本单元,由多个块组成
宏块中包含了宏块类型、预测类型、Coded Block Pattern 编码的块模式、Quantization Parameter 量化参数、像素的亮度和色度数据集等等信息

H264编码
编码器结构
一个编码器基本上都会有帧内预测、帧间预测、变换量化、熵编码以及滤波等几个部分。
预测编码是指利用相邻像素的空间或时间相关性,用已传输的像素对当前正在编码的像素进行预测,然后对预测值与真实值的差-预测误差进行编码和传输,即帧内预测,帧间预测。
变换编码是指将空间域描述的图像,经过某种变换形成变换域中的数据,改变数据分布,减少有效数据量。
编码流程
- 帧内预测:空间冗余
利用相邻像素的相关性,通过当前像素块的左边和上边的像素进行预测,计算出每个宏块的预测模式信息,再将预测得到的全部图像数据和当前帧原数据进行对比得到残差值,进行变换量化,拆包生成NAL分发
区别:帧内预测模式H264有9种;H265有35种,预测方向更细、更灵活 - 帧间预测:时间冗余
基于当前帧与参考帧,通过运动评估(对所有宏块匹配查找)得到运动矢量,与当前帧对比得出残差值,进行变换量化,生成NAL
区别:- H264以16x16宏块为预测单位,也可以划分为16x8, 8x8, 8x4, 4x4等;H265对应的是64x64的CTU,CTU可以递归的分解为编码块CU,CU是视频编码和帧间预测的基本单元,大小32x32, 16x16, 8x8等,可以进一步划分为PU和TU
- 采用了更合理的子像素插值算法,进一步提高了运动估计和运动补偿的精度
- 采用了新的合并模式,可以更加高效地编码传输运动参数
- 变换和量化:为了压缩残差信息的统计冗余
- DCT变换(离散余弦变换):将图像分成互不重叠的图像块,将空间域的图像信号变换到频率域。变换后,左上角的低频系数集中了大量能量,而右下角的高频系数上的能量很小,有益于有损压缩的数据处理
- 量化:人眼对图像的低频特性很敏感(如总体亮度),而对高频细节信息不敏感,因此在传送过程中可以少传高频信息。量化过程通过对低频区的系数进行细量化,高频区的系数进行粗量化,去除了人眼不敏感的高频信息,从而降低信息传送量。因此,量化是有损压缩,是视频压缩编码中质量损伤的主要原因
- 区别:H265提高了编码效率
- 熵编码:使用新的编码来表示输入的数据,从而达到压缩的效果
- 效率稍低、实现较易的基于上下文的自适应可变长编码(CAVLC),常用数据块用短码表示
- 效率较高、实现较难的基于上下文的自适应二进制算术编码(CABAC),目的是从概率的角度再做一次压缩,编码的过程主要分为二值化,上下文建模,二进制算术编码
- 环路滤波
视频压缩编码是有损压缩,逐块地对预测后的残差进行变换和量化,将导致重建图像时失真,出现方块效应(图像块边界上不连续)等。因此采用环路滤波的方法对重建图像进行滤波,降低重建误差- H264:去方块滤波(在 TU/PU 块边界进行不同强度滤波,减少重构图像会出现的方块效应)
- H265:去方块滤波、SAO样点自适应补偿(通过补偿重构像素值,以减少振铃效应)
压缩方式
1.帧内压缩(I帧,IDR帧):得到预测模式信息+残差值
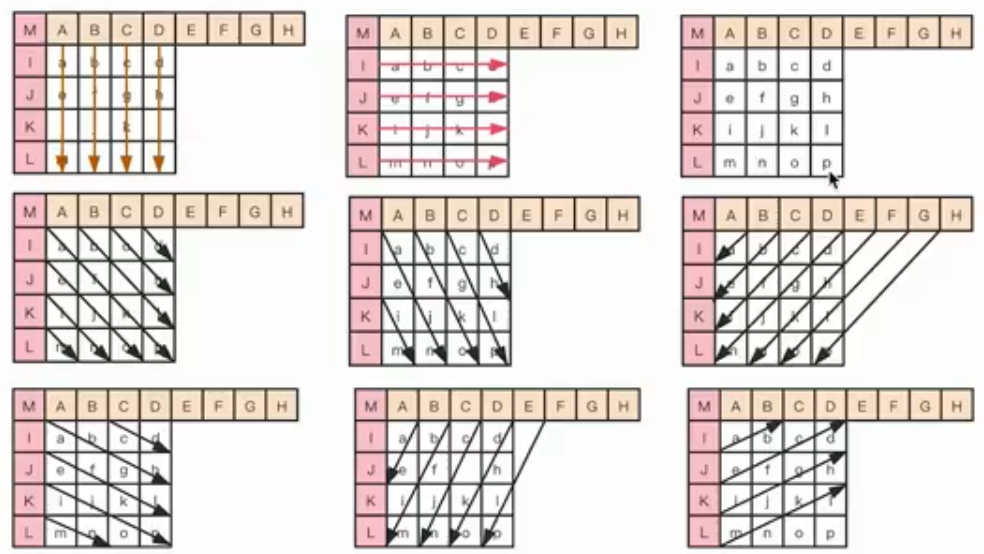
2.帧间压缩(P帧,B帧)
编码时运动估计:(通过宏块匹配)得到运动矢量+残差值
解码时运动补偿:将预测的图像与残差值相加
3.无损压缩
DCT变换、CAVLC压缩(MPEG2)、CABAC压缩(H.264)
AnnexB格式
AnnexB流结构
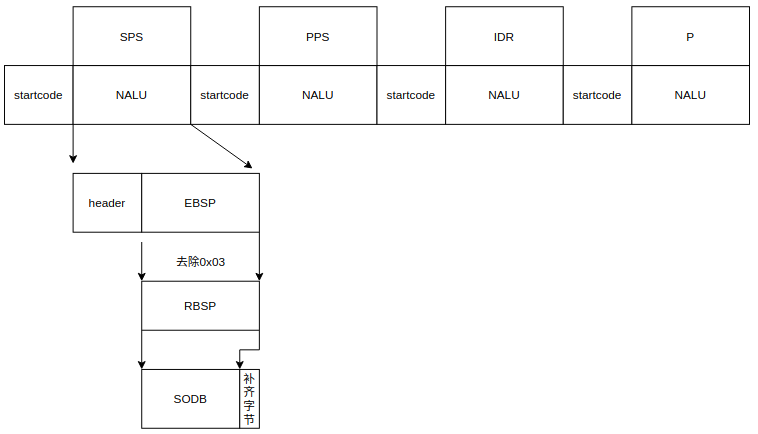
Startcode:
- 0x000001:单帧多slice(即单帧多个NALU)之间间隔
- 0x00000001:帧之间,或者SPS、PPS等之前
NALU:
- EBSP扩展字节序列载荷 = RBSP插入防竞争字节
0x03(连续两个0x00字节时) - RBSP原始字节序列载荷 = SODB + RBSP尾部(补齐)
- SODB为原始数据比特流 = Slice Header + Slice Data
SPS和PPS
- 序列参数集,包括一组编码视频序列的全局参数,包含了profile、level、宽高和颜色空间等信息
- 图像参数集,包括一幅图像的公共参数,PPS可以引用SPS参数,也会被码流中的slice引用
- 一般均位于码流起始,但也可能在中间:解码器需要从中间开始解码;编码过程中改变了参数
NALU Header(8 bits)
- 第一位:forbidden_zero_bit 禁止位,初始为0,当网络发现NAL单元有错误时可置为1
- 后两位:nal_ref_idc代表 NALU 的重要性,取值范围0~3。对于重要数据(参考帧,序列集参数集或图像集)必须大于0
- 最后五位:nal_unit_type指的是当前 NAL 类型
1-4:I/P/B帧,是依据VLC的slice区分的5:IDR帧,告诉解码器之前依赖的解码参数集合(接下来要出现的SPS\PPS等)可以被刷新了6:SEI补充增强信息,提供了向视频码流中加入额外信息的方法7:SPS序列参数集,保存了一组编码视频序列(Coded Video Sequence)的全局参数8:PPS图像参数集,保存了整体图像相关的参数9:AU分隔符,Access Unit是一个或者多个NALU的集合,代表了一个完整的帧
RBSP尾部
- RBSP尾部:大多数(非
1-5)NALU
SODB在最后紧跟1个比特1,再增加若干比特0补齐字节 - 条带RBSP尾部:NALU类型为条带(
1-5)时
默认仍情况1,仅当①entropy_coding_mode_flag值为1(当前采用的熵编码为CABAC)且②more_rbsp_trailing_data()返回true(RBSP中有更多数据时),添加一/多个0x0000
AVCC格式
AVCC流结构
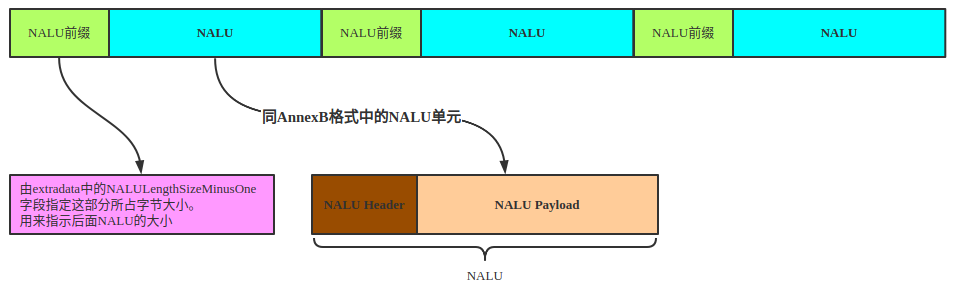
- 视频开始有
extradata,包含SPS、PPS和NALU前缀长度 - 前缀指明了NALU大小,前缀字节数1、2或4
- AVCC中的NALU格式与AnnexB一致。AVCC转AnnexB时,如果检测到NALU Type = 5关键帧,须在关键帧前面加上SPS NALU和PPS NALU即可
Extradata
前4字节无用跳过
第5个字节:前6位保留全1,后2位为NALU前缀大小,值013分别对应前缀124字节
第6个字节:前3位保留全1,后5位存放SPS NALU的个数(通常为1个)
根据SPS NALU个数,循环获取SPS数据:前2个字节为前缀,表示SPS字节数N,后N个字节为SPS的数据
获取全部SPS数据后,下个字节为PPS NALU的个数(通常为1个)
根据PPS NALU个数,循环获取PPS数据:前2个字节为前缀,表示PPS字节数N,后N个字节为PPS的数据
RTP格式
RTP封装= 12字节固定RTP包头 + 载荷(NALU)
RTP包头

- V:RTP协议的版本号为2
- P:填充标志,置1将在包尾包含附加填充字节,它不属于有效载荷。填充的最后一个八进制包含应该忽略的八进制计数。某些加密算法需要固定大小的填充字节,或为在底层协议数据单元中携带几个RTP包
- X:扩展标志,置1则在RTP报头后跟有一个扩展报头
- CC:CSRC计数器,指示CSRC 标识符的个数
- M:标记位(不同载荷含义不同,视频标记一帧的最后一个分片slice则1,其他0)
- PT:载荷类型RTP_PAYLOAD_RTSP,记录使用哪种 Codec ,receiver 端找出相应的 decoder解码出来。如H264=96
- 序列号:标识 RTP 报文的序列号(初始值随机),每发送一个报文序号加 1
- 时间戳:反映了该报文第一个八位组的采样时刻。 接受者使用时间戳来计算延迟和抖动, 并进行同步控制
- SSRC:区分是在和谁通信,两个同步信源的SSRC要相同
- CSRC:每个32位,可以有0~15个。每个CSRC标识了该报文有效载荷中的所有特约信源
NALU类型
最后五位:nal_unit_type指的是当前 NAL 类型
1-23:NAL单元,单个 NAL 单元包.24:STAP-A,单一时间的组合包25:STAP-B,单一时间的组合包26:MTAP16,多个时间的组合包27:MTAP24,多个时间的组合包28:FU-A,分片的单元29:FU-B,分片的单元
打包模式
单一NALU的RTP包(1个RTP包:1个NALU)
打包时去除
000..1开始码,把其他数据封包得 RTP 包即可组合NALU的RTP包(1个RTP包:多个NALU),需要解包时在重组,以STEP-A为例:
1
2
3[RTP Header] [78 (STAP-A头,1B)]
[第一个NALU长度(2B)] [67 42 A0 1E 23 56 0E 2F ]
[第二个NALU长度(2B)] [68 42 B0 12 58 6A D4 FF ... ]分片NALU的RTP包(1个NALU:多RTP包),因NALU>MTU
H265 /HEVC
H265码流结构
码流结构
H.265/HEVC压缩数据采用了类似H.264/AVC的分层结构,将数据GOP层、Slice层中公用的大部分语法元素游离出来组成SPS和PPS,并增加了视频参数集VPS。
- SPS 序列参数集,包括一组编码视频序列的全局参数,包含了profile、level、宽高和颜色空间等信息
- PPS 图像参数集,包括一幅图像的公共参数,引用关系 slice -> PPS -> SPS ->VPS
- VPS 视频参数集,包括多个子层共享的语法元素和其他不属于SPS的特定信息
分层结构
视频序列划分为GOP(开放式)
GOP包含多个Slice或Tile,为了独立编解码
- Slice带状,包括一个独立片段SS和若干依赖SS,SS包含多个树形编码单元CTU
- Tile矩形,包含整数个CTU
CTU按照四叉树划分为不同类型,包括CU、PU、TU
- CU是进行预测、变换、量化和熵编码等处理的基本单元
- PU是进行帧内/帧间预测的基本单元
- TU是进行变换和量化的基本单元
AnnexB与HVCC格式
H.265的优势/区别
- H.265的编码架构和H.264相似,包含帧内预测、帧间预测、转换、量化、去区块滤波器、熵编码。但在HEVC编码架构中,整体被分为了三个基本单位,分别是编码单元CU、预测单元PU和转换单元 TU。并且对一些技术加以改进:改善码流、编码质量、算法复杂度
- H.265采用了块的四叉树划分结构,采用了从64×64~8×8像素的自适应块划分,并基于这种块划分结构采用一系列自适应的预测和变换等编码技术;而H.264中每个宏块大小都是固定的16×16像素
- H.265的帧内预测模式支持35种方向(H.264只支持9种),预测方向更细、更灵活
- H.265的帧间预测采用了更合理的子像素插值算法,提高了运动补偿和估计的精度
- H.264可以低于1Mbps的速度实现标清数字图像传送;H.265则可以实现利用1~2Mbps的速度传送720P普通高清音视频
- 同样的画质和同样的码率,H.265比H.264占用的存储空间要少理论50%
档次、层和级别
Profile(3种):主要规定编码器可采用哪些编码工具或算法
H.264有四种画质级别:
Baseline Profile:基本画质。支持I/P 帧,只支持无交错和CAVLC
Extended profile:进阶画质。支持I/P/B/SP/SI 帧,只支持无交错和CAVLC
Main profile:主流画质。提供I/P/B 帧,支持无交错和交错,也支持CAVLC 和CABAC
High profile:高级画质。在main Profile 的基础上增加了8x8内部预测、自定义量化、无损视频编码Level(13种):根据解码端的负载和存储空间情况对关键参数加以限制,主要包括采样率、分辨率、码率的最大值、压缩率的最小值、解码图像缓存区的容量(DPB)、编码图像缓存区的容量(CPB)等
Tier(2种):H.265新定义的,规定了每个级别的码率的高低