文件系统读写
address_space 指示文件在页缓存中已经缓存了的物理页,是页缓存和外部设备中文件系统的桥梁
读文件
- read()函数根据传入的文件路径,在目录项中检索,找到该文件的inode
- 在inode中,通过文件内容偏移量计算出要读取的页
- 通过inode找到文件对应的address_space,在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
- 如果页缓存命中,那么直接返回文件内容
- 如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存
写文件
- 找到inode,进一步找到文件对应的address_space
- 在address_space中查询对应页的页缓存是否存在:
- 如果页缓存命中,直接修改完页缓存的页中就写结束了,并没有写回到磁盘文件中去
- 如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页。此时缓存页命中,进行第6步。
- 页缓存被修改后会被标记成脏页。脏页需要写回到磁盘中的文件块:调用
sync()/fsync(),或等pdflush进程定时把脏页写回到磁盘。脏页写回过程中会上锁,其他写请求被阻塞
内存资源管理
Buffers/Cached
在内存管理中的buffer指Linux内存的:Buffer cache,cache指Linux内存中的:Page cache。
如果有内存是以page进行分配管理的,都可以使用page cache来缓存。以 block 进行管理的内存可以通过buffer cache来缓存。 Page Cache 用于缓存文件的页数据,buffer cache 用于缓存块设备(如磁盘)的块数据。 块的长度主要是根据所使用的块设备决定的,而页长度都是4k。
什么是page cache
Page cache主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有read/write操作的时候。仔细想想的话,作为可以映射文件到内存的系统调用:mmap是不是很自然的也应该用到page cache?malloc会不会用到page cache?
在当前的实现里,page cache也被作为其它文件类型的缓存设备来用,所以事实上page cache也负责了大部分的块设备文件的缓存工作。
什么是buffer cache
Buffer cache则主要是设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。但是由于page cache也负责块设备文件读写的缓存工作,于是,当前的buffer cache实际上要负责的工作比较少。这意味着某些对块的操作会使用buffer cache进行缓存,比如我们在格式化文件系统的时候。
一般情况下两个缓存系统是一起配合使用的,比如对一个文件进行写操作的时候,page cache的内容会被改变,而buffer cache则可以用来将page标记为不同的缓冲区,并记录是哪一个缓冲区被修改了。这样,内核在后续 writeback 时,就不用将整个page写回,而只需要写回修改的部分即可。
buffer/cache 不等同于空闲内存。内核需要维持内存缓存的一致性,在脏数据产生较快或数据量较大的时候,缓存系统整体的效率一样会下降,因为毕竟脏数据写回也是要消耗IO的。进程申请内存时,内核可以将buffer/cache占用的内存当成空闲的内存分给进程,但是其成本是内核会进行脏数据写回,保证数据一致后才会清空并分给进程使用。如果进程突然申请大量内存,而且业务是一直在产生很多脏数据(比如日志),并且系统没有及时写回的时候,此时系统给进程分配内存的效率会很慢,系统IO也会很高。
进程使用的用户空间内存映射包括文件影射(file)和匿名影射(anon)。
- 匿名影射主要是诸如进程使用malloc和mmap的MAP_ANONYMOUS的方式申请的内存
- 文件影射就是使用mmap影射的文件系统上的文件,这种文件系统上的文件既包括普通的文件,也包括临时文件> 系统(tmpfs)。这意味着,Sys V的IPC和POSIX的IPC(共享内存,信号量数组和消息队列)都是通过文件影> 射方式体现在用户空间内存中的。这两种影射的内存都会被算成进程的RSS,但是也一样会被显示在cache的内存计数中。
进程申请内存会发生什么
申请内存不会真正的让内核去给进程分配一个实际的物理内存空间。真正会触发分配物理内存的行为是缺页异常。
缺页异常的处理过程大概可以整理为以下几个路径:
首先检查要访问的虚拟地址是否合法,如果合法则继续查找和分配一个物理页,步骤如下:
如果该虚拟地址在物理页表中不存在
- 如果是匿名影射,则申请置0的匿名影射内存,此时也有可能是影射了某种虚拟文件系统,比如共享内存,那么就去影射相关的内存区,或者发生COW写时复制申请新内存。
- 如果是文件影射,则有两种可能,一种是这个影射区是一个page cache,直接将相关page cache区影射过来即可,或者COW新内存存放需要影射的文件内容。如果page cache中不存在,则说明这个区域已经被交换到swap空间上,应该去处理swap。
如果页表中已经存在需要影射的内存
则检查是否要对内存进行写操作,如果不写,那就直接复用,如果要写,就发生COW写时复制。
分配内存过程先会检查空闲页表中有没有页可以申请,实现方法是:get_page_from_freelist。如果空闲中没有,则处理过程的主逻辑大概这样:
- 唤醒kswapd进程,把能换出的内存换出,让系统有内存可用。
- 继续检查看看空闲中是否有内存。有了就ok,没有继续下一步:
- 尝试清理page cache,清理的时候会将进程置为D状态。如果还申请不到内存则:
- 启动oom killer干掉一些进程释放内存,如果这样还不行则:
- 回到步骤1再来一次!
以上逻辑中,不仅仅只有清理cache的时候会使进程进入D状态,还有其它逻辑也会这样做。这就是为什么在内存不够用的情况下,oom killer有时也不生效,因为可能要干掉的进程正好陷入这个逻辑中的D状态了。
IO缓存
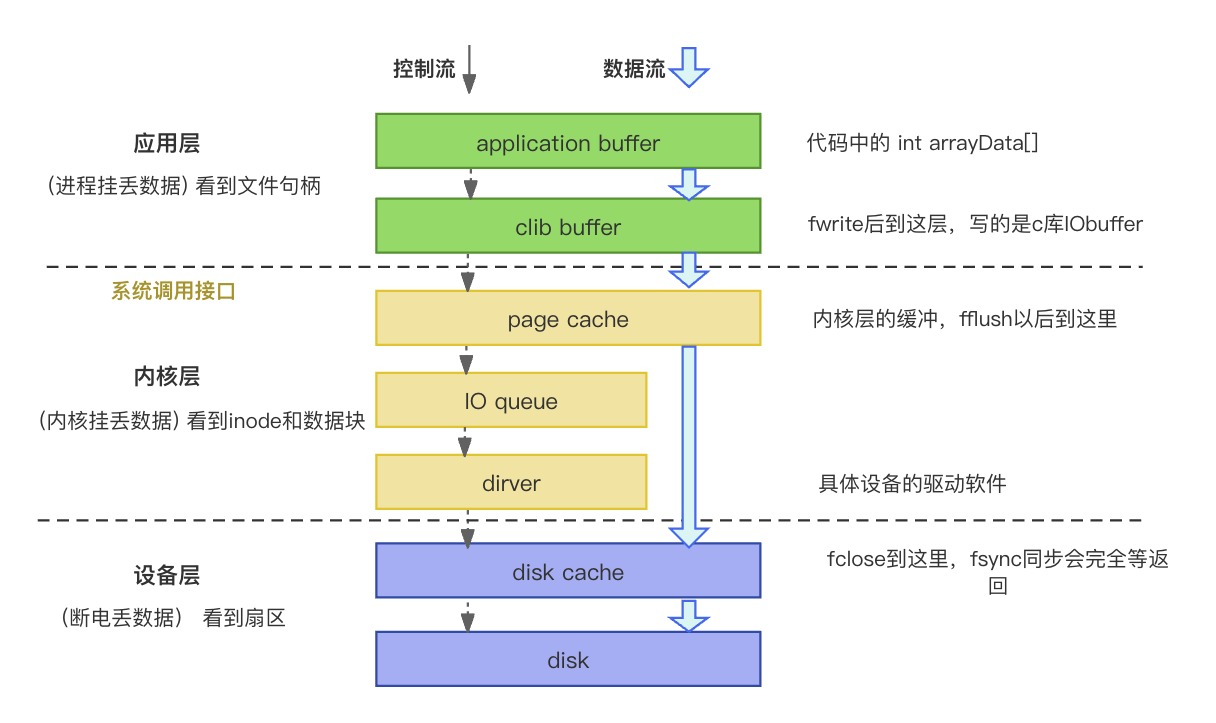
库缓冲
为啥要有库缓冲(如clib buffer)
因为从应用层到内核层需要系统调用、内核态切换,开销比较大,为了减少调用次数
绕过库缓冲的方案
用mmap(内存映射文件),把内核空间的page cache映射到用户空间。
内核缓冲
为啥要有内核缓冲
内核用pdflush线程循环检测脏页,判断是否写回磁盘。
由于磁盘是单向旋转,重新排布写操作顺序可以减少旋转次数。(合并写入)
O_SYNC参数: 访问内核缓冲时是异步还是同步。O_SYNC表示同步。
绕过内核缓冲的方案
用O_Direct参数,直接怼Disk cache。
磁盘缓冲
为啥要有磁盘缓冲
驱动通过DMA,将数据写入磁盘cache。
磁盘缓冲主要是保护磁盘不被cpu写坏。是与外部总线交换数据的场所。(断电丢数据)
绕过磁盘缓冲的方案
用RAW设备写,直接写扇区: fdisk,dd,cpio工具。
共享内存
共享内存
共享内存就是多个进程间共同使用同一段物理内存空间,它是通过将同一段物理内存映射到不同进程的虚空间中来实现的。由于映射到不同进程的虚拟地址空间中,不同进程可以直接使用,不需要进行内存的复制,所以共享内存的效率很高。
优点:共享内存(shared memory)是最简单的最大自由度的Linux进程间通信方式之一。使用共享内存,不同进程可以对同一块内存进行读写。由于所有进程对共享内存的访问就和访问自己的内存空间一样,而不需要进行额外系统调用或内核操作,同时还避免了多余的内存拷贝,这种方式是效率最高、速度最快的进程间通信方式。
缺点:内核并不提供任何对共享内存访问的同步机制,比如同时对共享内存的相同地址进行写操作,则后写的数据会覆盖之前的数据。所以,使用共享内存一般还需要使用其他IPC机制(如信号量)进行读写同步与互斥。
原理:内核对内存的管理是以页为单位的(4k)。而程序本身的虚拟地址空间是线性的,创建共享内存空间后,内核将不同进程虚拟地址的映射到同一个页面。所以在不同进程中,对共享内存所在的内存地址的访问最终都被映射到同一页面。
Linux的实现机制
System V共享内存:持久化的,除非被进程明确的删除,否则关机前始终存在于内存中POSIXmmap文件映射实现共享内存:非持久化的,随着进程关闭,映射会随即失效
虽然 System V 与 POSIX 共享内存都是通过 tmpfs 实现,但由于内核在mount tmpfs时,指定了MS_NOUSER,所以该tmpfs没有大小限制。因此/proc/sys/kernel/shmmax只会限制 System V 共享内存,/dev/shm只限制Posix共享内存,默认是物理内存的一半。
tmpfs
一种基于内存的临时文件系统,tmpfs可以使用RAM,但它也可以使用swap分区来存储。传统的ramdisk是个块设备,要用mkfs来格式化它,才能真正地使用它;tmpfs是一个文件系统,并不是块设备,安装即可以使用。tmpfs是最好的基于RAM的文件系统,动态文件系统大小 & 存取速度快
/dev/shm
是利用内存虚拟出来的磁盘空间。通常是内存空间大小的一半,该目录下创建的文件存取速度优于普通硬盘挂载的目录下的文件,该目录下的文件在机器重启时会丢失。
System V共享内存
基本介绍
System V 是Unix操作系统众多版本中的一支,一共发行了4个 System V 的主要版本:版本1、2、3和4。
System V 共享内存机制为了在多个进程之间交换数据,内核专门留出了一块内存区域用于共享,共享这个内存区域的进程就只需要将该区域映射到本进程的地址空间中即可。内核直接实现了shmget / shmat系统调用,最终也是靠tmpfs来实现的。
System V 的IPC对象有共享内存、消息队列、信号量。注意:在IPC的通信模式下,不管是共享内存、消息队列还是信号灯,每个IPC的对象都有唯一的名字,称为”键(key)”。通过”键”,进程能够识别所用的对象。”键”与IPC对象的关系就如同文件名称于文件,通过文件名,进程能够读写文件内的数据,甚至多个进程能够公用一个文件。而在IPC的通信模式下,通过”键”的使用也能使得一个IPC对象能为多个进程所共用。
使用步骤
共享内存的使用过程可分为 创建->连接->使用->分离->销毁 这几步。
- 创建/打开共享内存
- 映射共享内存,即把指定的共享内存映射到进程的地址空间用于访问
- 撤销共享内存的映射
- 删除共享内存对象
执行过程先调用shmget,获得或者创建一个IPC共享内存区域,并返回获得区域标识符。类似于mmap中先open一个磁盘文件返回文件标识符一样。
再调用shmat,完成获得的共享区域映射到本进程的地址空间中,并返回进程映射地址。类似与mmap函数原理。
使用完成后,调用shmdt解除共享内存区域和进程地址的映射关系。每个共享的内存区,内核维护一个struct shmid_ds信息结构,定义在sys/shm.h头文件中
相关API
https://bbs.huaweicloud.com/blogs/316187
示例代码
1 | /***** writer.c *******/ |
POSIX mmap实现共享内存
基本介绍
POSIX 表示可移植操作系统接口(Portable Operating System Interface),POSIX 标准定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称,其正式称呼为 IEEE 1003,而国际标准名称为 ISO/IEC 9945。
POSIX 提供了两种在无亲缘关系进程间共享内存区的方法:
- 内存映射文件,由open函数打开,由mmap函数把所得到的描述符映射到当前进程空间地址中的一个文件。
- 共享内存区对象(shared-memory object),由shm_open函数打开一个POSIX IPC名字,所返回的描述符由mmap函数映射到当前进程的地址空间。
这两种共享内存区的区别在于共享的数据的载体(底层支撑对象)不一样:内存映射文件的数据载体是物理文件;共享内存区对象,也就是共享的数据载体是物理内存。共享内存,一般是指共享内存区对象,也就是共享物理内存。
Posix的共享内存机制实际上在库过程中以及用户空间的其他部分被展示为完全的文件系统的调用过程,在调用完shm_open之后,需要调用mmap来将tmpfs的文件映射到地址空间,接着就可以操作这个文件了,需要注意的是,别的进程也可以操作这个文件,因此这个文件其实就是共享内存。
相关API
https://bbs.kanxue.com/thread-275275.htm
示例代码
1 | // gcc writer.c -lrt -o writer |
写放大原因
读写单元较大
文件系统的写放大:如果write的数据小于4K,则要先把整块读入,再修改,再把新的4K整体写入(O_DIRECT情况除外),这个过程可以称为 RMW (Read-Modify-Write)。
再如,在DBMS等应用层存储系统中,同样存在自己管理的读写单元,如MySQL的默认读写单元称为页,默认是16KB,所以一次读写只能以页的单位进行,造成了“写放大”。
RAID中的RMW
RAID中更新一个块,需要额外读原始块、校验块,额外写校验块,所以多了两个读,一个写,也称为Read-Modify-Write。这是由于校验块必须更新,且根据异或运算的可逆性,新校验块=新数据块^旧校验块^旧数据块。
SSD中闪存特性
在SSD中,一个block可以分为多个page,在读的时候,可以以page为单位,但是写的时候,只能以block为单位,因此写的单元比较大。同样是读写1个page的大小,读的话直接读就行,写的话却需要先把与要写page同一个block的数据全复制一遍,加上修改的page后,再一起写入block。
存储系统一致性机制
在存储系统的很多层次中,都有保证系统crash consistency(一致性)的设计。因此,不管是应用层的存储系统(如DBMS、KV-store)、虚拟化层中的镜像管理、系统层的文件系统,都要通过强制同步各种元数据的写入顺序,或者利用 redo log 的思想,用journaling、log-structured或copy-on-write等策略保证元数据写入目的位置生效前先完整地生成日志,来保证系统崩溃或断电时,元数据之间是一致。但是,如果多层存储系统重叠,由于一致性机制导致同步次数增加就会层层放大。
比如,运行在x86虚拟机中的levelDB,其一次更新操作就会
- 最终导致levelDB写log文件和写数据两次同步写,这两次写就又会
- 导致2次的Guest文件系统log写和2次Guest文件系统数据写,一共4次同步写,这4次写又会导致
- 虚拟化镜像管理层的4 x N次写(N取决于镜像为保证元数据crash consistency的同步次数,若是qcow2格式,N可能有5次之多),最后导致:
- Host文件系统的4 x N x 2 = 8 x N次同步写。当然这是一种比较极端的情况,但实际应用中也应该存在。
LSM树KV系统的Merge操作
levelDB等KV存储广泛采用了LSM树等结构进行存储组织,其特点就是靠上的level的数据会最终被merge sort到下层,由于多数level在磁盘文件中,这也就导致了同一KV数据的总写放大,放大的倍数就是大约是level的数目。