STL函数
1 | /* 非修改式 */ |
Vector
Emplace vs Push
1. push 和 emplace
考虑向vector插入字符串的场景,vector的push_back被按左值和右值分别重载:
1 | template <class T, class Allocator = allocator<T>> |
在调用 vec.push_back("xyzzy") 时发生如下过程:
- 第一次构造函数,从
const char[6]的 xyzzy 创建一个 string 临时对象,这个对象是右值 - 临时对象被传递给 push_back 的右值重载函数,绑定到右值引用形参 x。第二次移动构造函数将 x 副本拷贝到 vector 内部,因为 x 在它被拷贝前被转换为一个右值,成为右值引用
- 在 push_back 返回之后,string 临时对象被销毁,发生一次析构
相比之下,emplace_back 使用完美转发,使用传递的实参直接在 vector 内部构造一个 string,仅用了一次构造函数
2. 何时 emplace 优于 push
- 值被构造到容器中,而不是直接赋值
- 传入的类型与容器的元素类型不一致
- 容器不拒绝已经存在的重复值:emplace 会创建新值的节点,以便将该节点与容器中节点的值比较。如果值已经存在,置入操作取消,创建的节点被销毁,意味着构造和析构时的开销被浪费了,如
map, unordered_map
3. 为什么用 emplace_back 时报错缺失拷贝构造函数
直观上,emplace_back() 原地构造,不会发生拷贝/移动构造。但如果 vector 没有预先 reserve 空间,在空间扩张过程中就会发生拷贝。
[TODO] 默认调用拷贝构造函数,将其 delete 标记后,变成了调用移动构造函数,具体机制是啥?另外虽然 reserve 预分配空间能实现 真·原地构造,全程不需要拷贝/移动构造函数,但如果 delete 掉这俩函数就过不了编译,那么能推出编译层面是硬性要求?
线程安全
core dump的情况
- 单线程写入,但是并发读的时候,由于潜在的内存重新申请和对象复制问题,会导致读方的迭代器失效
- 多个写方并发的push_back()
解法一:加锁
互斥锁性能较差 lock_guard<mutex>
读写锁(共享独占锁)适合读多写少,shared_lock<shared_mutex> 与 unique_lock<shared_mutex>
解法二:lock-free
固定vector的大小,避免动态扩容(无push_back),但同时对一个下标读写还是有问题
- 初始化
resize好N个对象(预留内存+构造函数),可以改成环形队列缓解压力 - 多线程读写都通过容器的下标访问元素,不要
push_back新元素 - 把队列头的下标定义成原子变量
std::atomicvector::operator[]可返回除了 bool 以外的任何类型
布尔数组
vector<bool> 使用打包形式(packed form)表示它的bool,用 unsigned long 作为存储 bool 的基本类型,每个bool占一个bit。
这给 vector::operator[] 带来了问题,因为 vector<T>::operator[] 应当返回一个 T&,但是C++禁止对bits的引用,无法返回 bool&,所以 vector<bool>::operator[] 返回一个行为类似于 bool& 的对象 vector<bool>::reference
vector<bool>::reference 为了能模拟 bool& 的行为,可以向 bool 隐式转化(而非&bool),但这在某些情况会有问题:
1 | vector<bool> bits{true, true, false}; |
- b1:
operator[]返回vector<bool>::reference对象,通过隐式转换赋值给 bool 变量 b1,表示第五个bit的值符合预期 - b2:
operator[]返回vector<bool>::reference对象,auto推导 b2 的类型为vector<bool>::reference,但此对象没有第五bit的值,具体取决于实现
自定义比较
1.Lamda
1 | auto cmp=[&](const node& a, const node& b) { |
2.仿函数
广泛适用于 STL:sort, set, map, priority_queue, lower_bound, merge
缺点:不能访问外部对象
1 | struct cmp{ |
3.比较符重载
1.结构体内部运算符重载
1 | struct node{ |
2.外部运算符重载
1 | bool operator< (const node &a, const node &b) { |
STL原理
空间配置器
new 和 delete 都包含两阶段操作:
- 对于 new 来说,先调⽤ ::operator new 分配内存,然后构造对象。
- 对于 delete 来说,先析构对象,然后调⽤ ::operator delete 释放空间。
STL allocator 将这两个阶段操作区分开来:
- 对象构造由 ::construct() 负责;对象释放由 ::destroy() 负责。
- 内存配置由 alloc::allocate() 负责;内存释放由 alloc::deallocate() 负责;
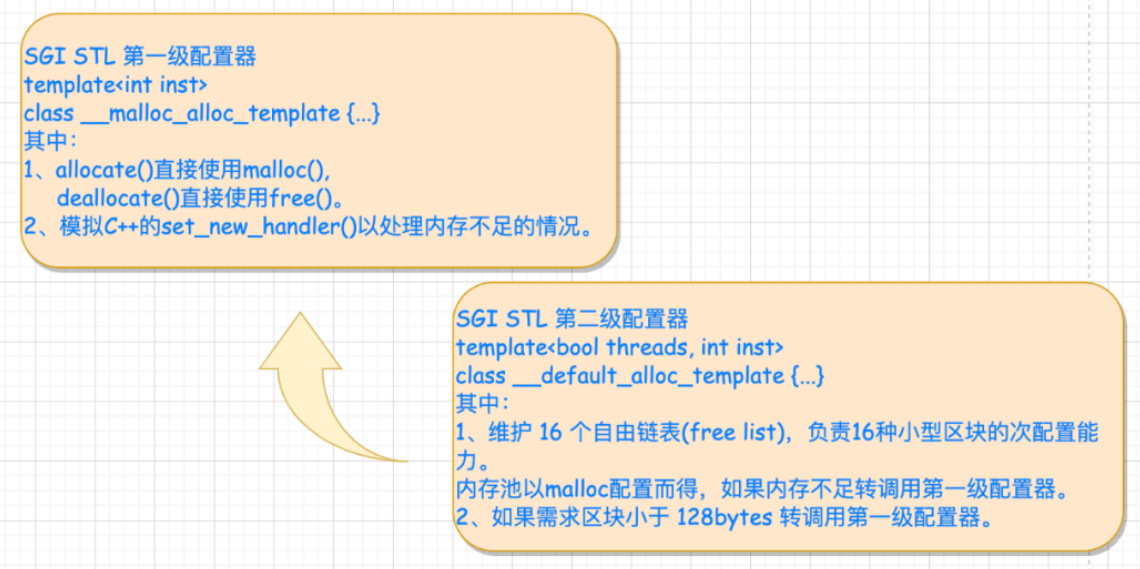
alloc ⼀级配置器
- 第⼀级配置器以
malloc(),free(),realloc()执⾏实际的内存配置、释放和重配置操作,并实现类似
C++ new-handler 的机制(自定义异常处理、尝试释放内存、abort等)。 - 第⼀级配置器的
allocate()和reallocate()在调⽤malloc() 和 realloc() 不成功后,改调⽤oom_malloc() 和oom_realloc()。 oom_malloc()和oom_realloc()都有内循环,不断调⽤“内存不⾜处理例程”,期望某次调⽤后,获得⾜够的内存⽽完成任务。如果⽤户并没有指定“内存不⾜处理程序”,STL 便抛出异常或调⽤exit(1)。
alloc ⼆级配置器
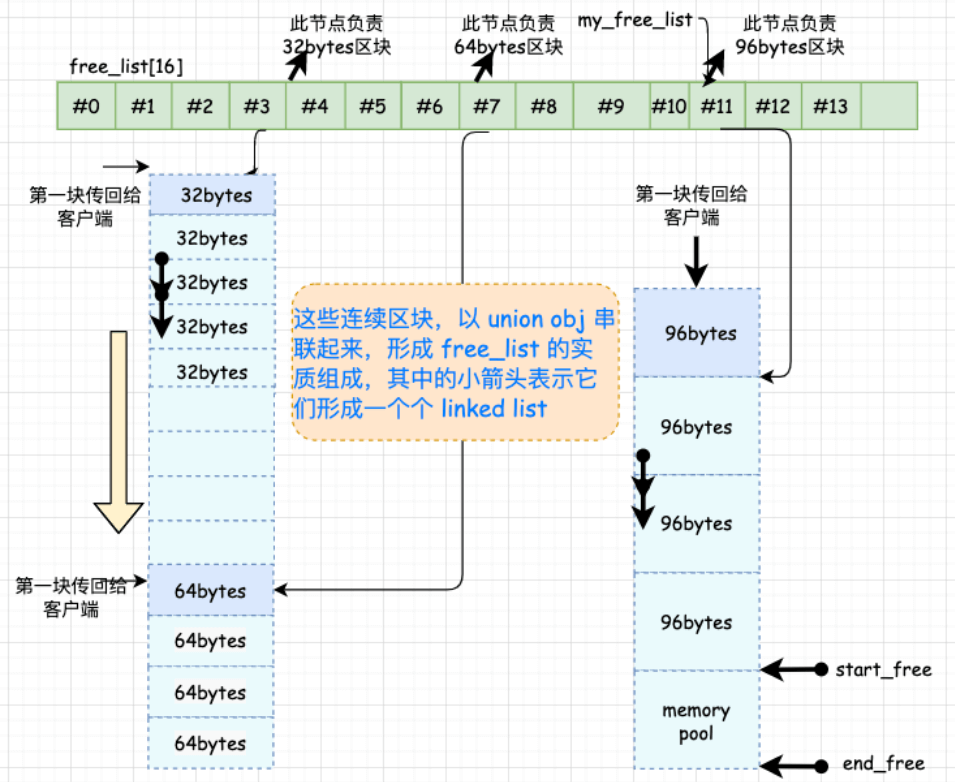
内存池原理:每次配置一大块内存,进行切分小区块,二级配置器将这些不同大小的区块用16个自由链表维护,并将小额内存需求量上调至8的倍数,这些内存空间是cookie free的
1. 空间申请
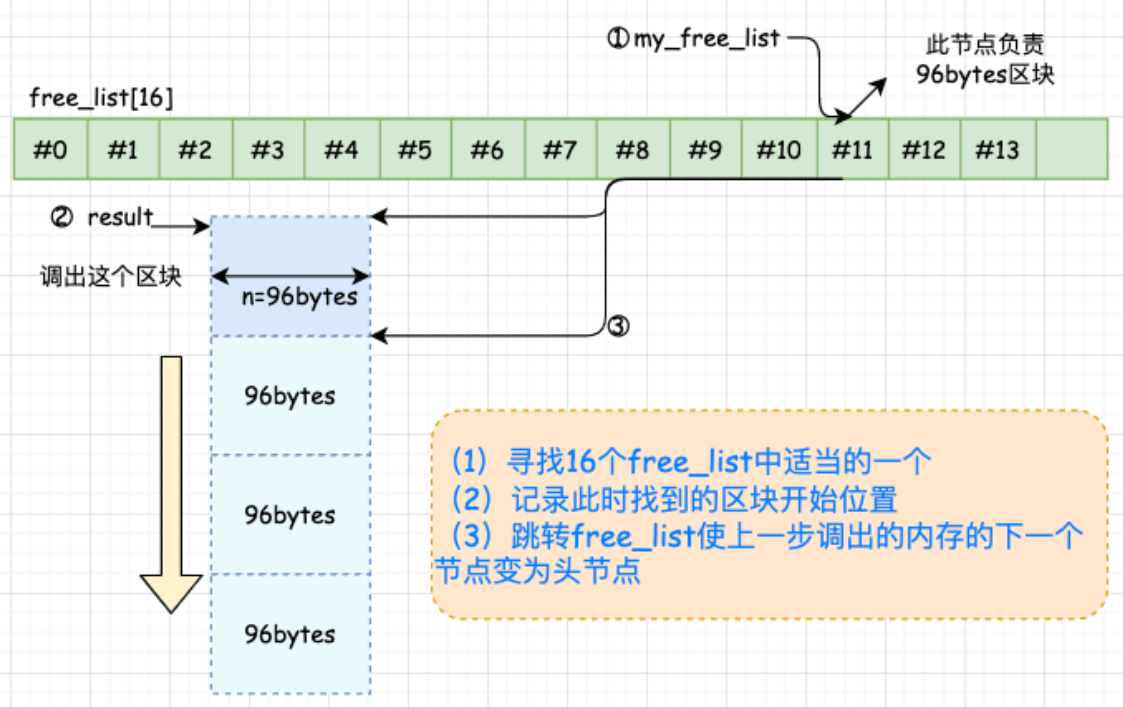
2. 空间释放
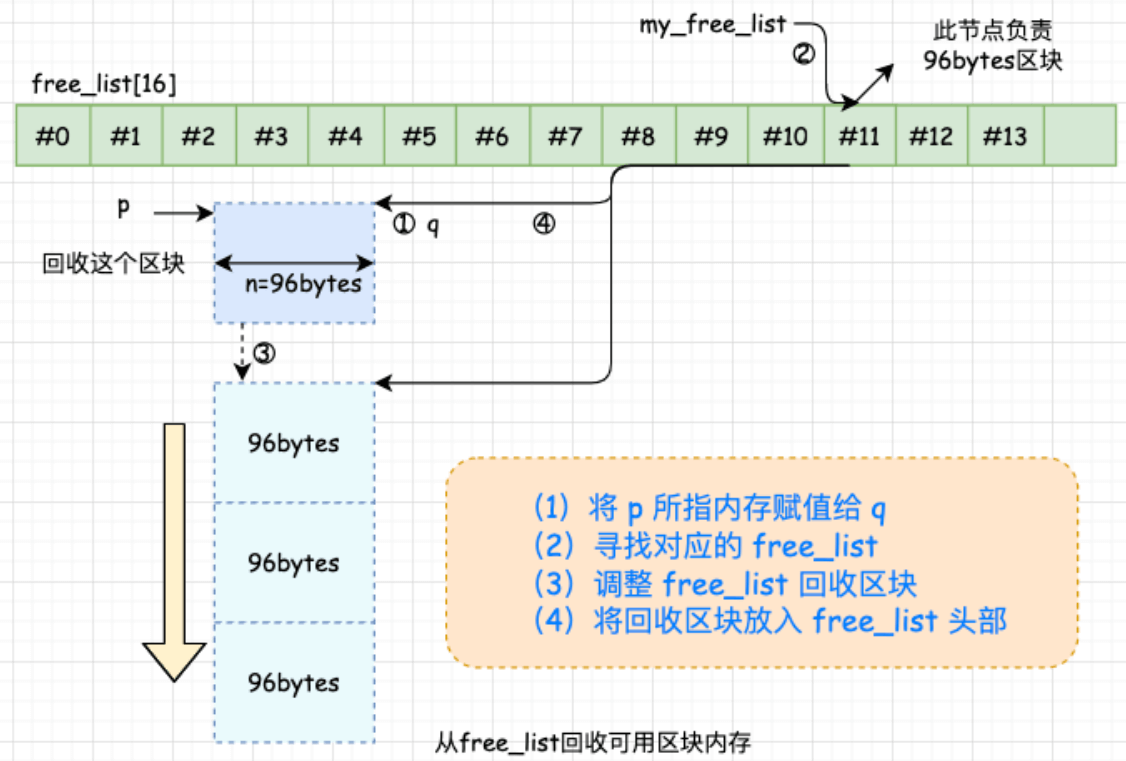
3. 重新填充 free_lists
- 当发现 free_list 中没有可⽤区块时,就会调⽤ refill() 为free_list 重新填充空间;
- 新的空间将取⾃内存池,用 chunk_alloc() 分配;
- 默认分配20个新区块,若内存池空间不足也可能⼩于 20。
4. 内存池
从内存池中取空间“切分”出free-list,是chunk_alloc()在工作:
- 若内存池还有余额空间
- 水量=0:调用malloc()从heap中配置内存(2倍需求量)
- 水量>0:调出最多20区块给free-list
- 系统堆内存空间不足,malloc()失败
- 从free-list中向上空间更大且未用的区块
- 若没找到则调用一级配置器,再失败则bad_alloc()
Vector
与array的区别
- 创建方式上不同:vector无需指定大小只需指定类型,array需要同时指定类型和大小
- 内存使用上不同:vector需要占据比array更多的内存,因为其内存空间大小是动态可变的
- 效率上不同:vector效率偏低,空间扩容时可能整个位置发生改变,需要将原来空间里的数据拷贝过去
- 下标类型不同:vector为vector::size_type,数组下标则是 size_t
- swap操作不同:vector是将引用进行交换,效率高;array是进行值的交换,效率低
注意:size_t表示元素个数,能表示的范围和系统位数有关,因为int、long是固定的可能不够用;vector::size_type和size_t同理,但其是容器概念
Traits
增加⼀层中间的模板 iterator_traits ,以获取迭代器的型别,其原理为:
- 模板参数推导机制:获取迭代器型别
- 内嵌类型定义机制:推导函数返回值类型
- 偏特化机制:处理原⽣指针和const指针
iterator_traits:特性萃取机,负责萃取迭代器的特性,有以下五种:
1 | value_type //迭代器所指对象的型别 |
type_traits:负责萃取型别的特性。可以针对不同的型别,在编译期间完成函数派送决定。例如,当容器内的元素类型拥有非平凡拷贝赋值函数时,应该多次调用拷贝赋值函数进行拷贝,但如果拥有平凡拷贝赋值函数,直接 memcpy() 或 memmove() 对元素进行内存拷贝就行了。
1 | has_trivial_default_constructor |
Traits编程
1 |
|
Deque
Deque是双向开口的连续线性空间,实际是由动态的以分段空间组合而成。能在常数时间进行头尾操作,提供随机访问迭代器。
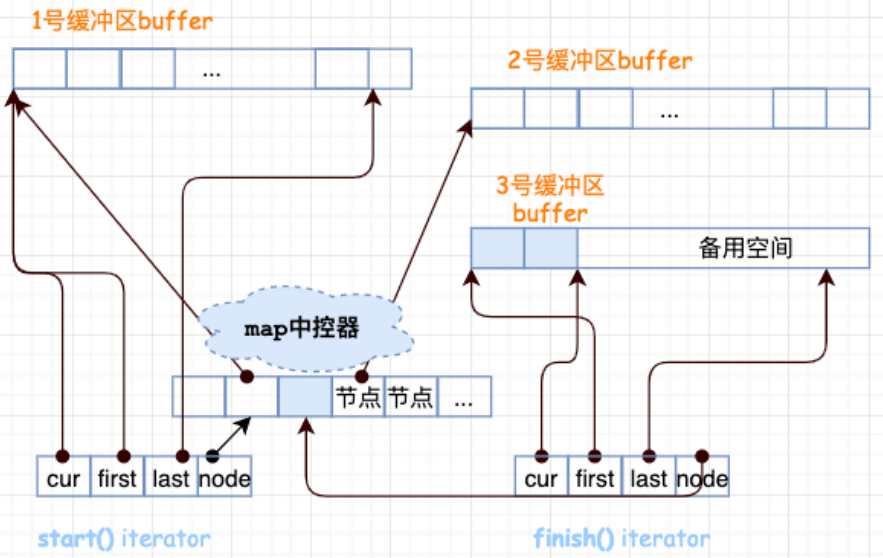
Deque 采⽤⼀块所谓的 map 作为中控器,⼀⼩块连续空间中的每个元素都是指针,指向另外⼀段较⼤的连续线性空间,称之为缓冲区。
迭代器:Deque用 start 和 finish 两个迭代器指向首尾两端的连续空间。每个迭代器包含4个指针:first、cur、last指向缓冲区中,node二级指针是map中指向当前缓冲区指针的指针
扩容:首尾端的节点备⽤空间不⾜时,配置⼀个新的map,申请更⼤的空间,拷⻉元素过去,修改 map 和 start,finish 的指向。
删除:判断删除的位置是中间偏后还是中间偏前来进⾏移动。
Hashtable
- 冲突:用链地址法解决hash冲突(开放定址:线性探测、二次探测,再散列法)
- 构成:buckets用vector存储,迭代器只能向前,bucket维护的链表是自定义数据结构组成的linked-list
- 容量:hashtable的容量选择≥元素个数的质数(28个中)。当负载因子 loadFactor<=1时,hash表查找的期望复杂度为O(1)。当Hash表中每次发现loadFactor =1时,就开辟一个原来桶数组的两倍空间,然后把原来的桶数组中元素全部重新哈希到新的桶数组中。
Set (红黑树)
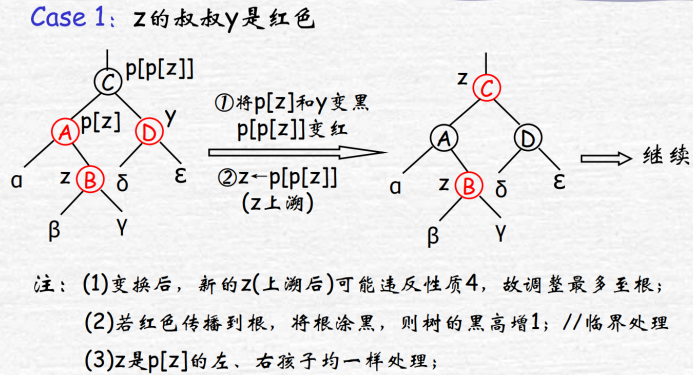
插入:按二叉搜索树插入z后涂红,可能违反红红性质,当z.p为左节点时分为三种情况:
z红叔:将父叔爷结点染反色,视角移到爷结点迭代判断
z黑叔,且为右子节点:父节点左旋变为3
z黑叔,且为左子节点:爷节点右旋,并把父爷结点染色
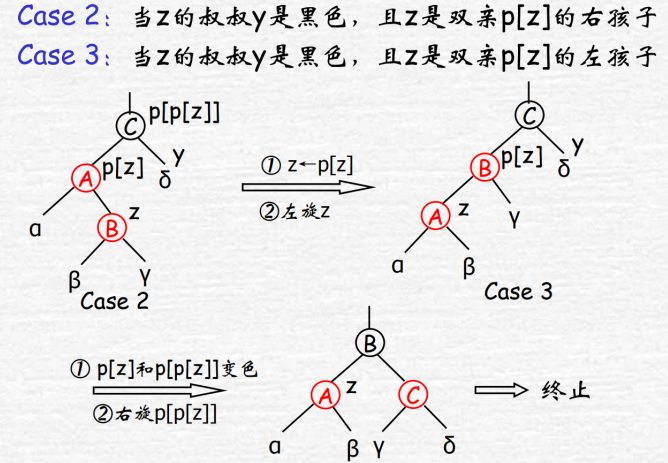
2,3调整完毕,1不断向上迭代,最多旋转两次
删除:z为子节点直接删,有一个子节点则让子节点取代,两个子节点则用中序后继节点y取代自己(右子树最左的结点y,覆盖z的值),此时实际转为删除y,让y的右子节点x取代y
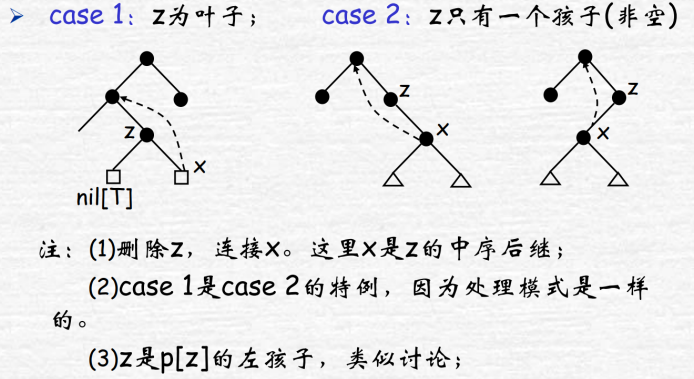
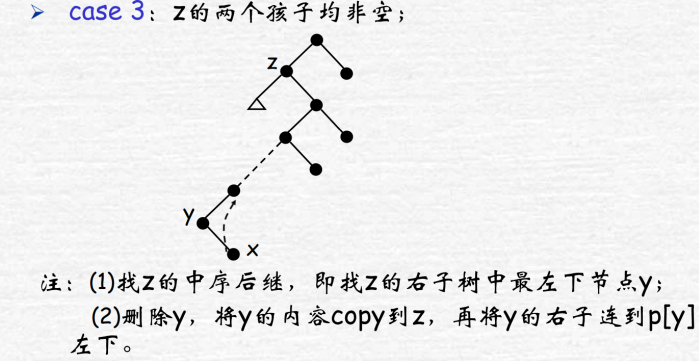
如果被删的y是黑色则需要调整,想象将y的黑色涂到x上弥补黑高
- 如果x是根,直接结束,相当于整体黑高减一
- 如果x为红,直接染黑结束
- 否则x为黑,则此时为双黑,需要变色、旋转把多余一层黑色向上传播,直到某个红结点或根
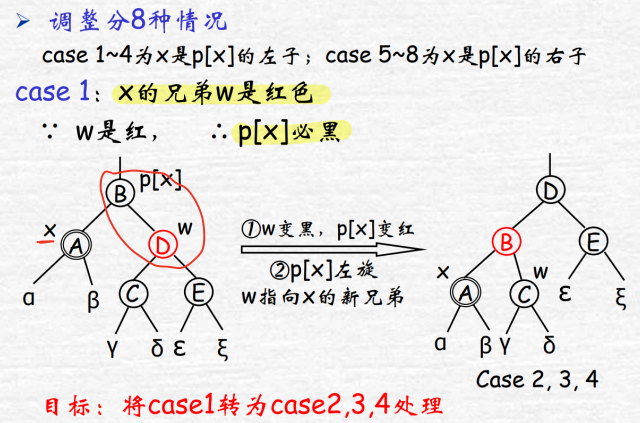
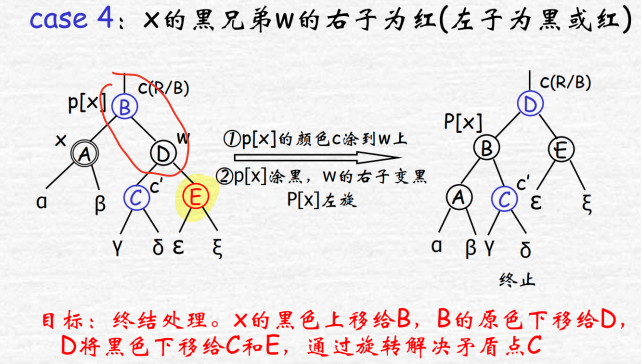
考虑x为左子节点时,兄弟结点w,分为四种情况:
w红:将w染黑,父结点左旋变成情况2,3,4
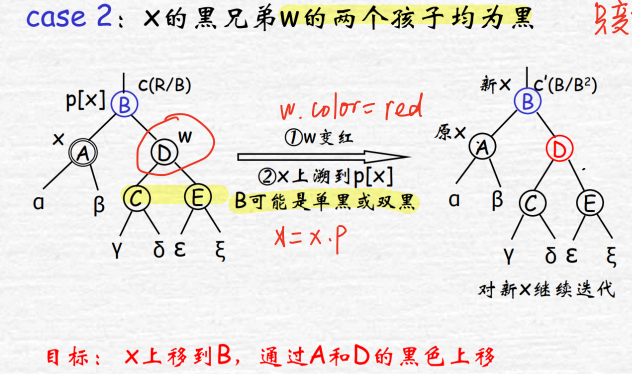
w黑且子双黑:将w变红,视角移到上一层迭代判断
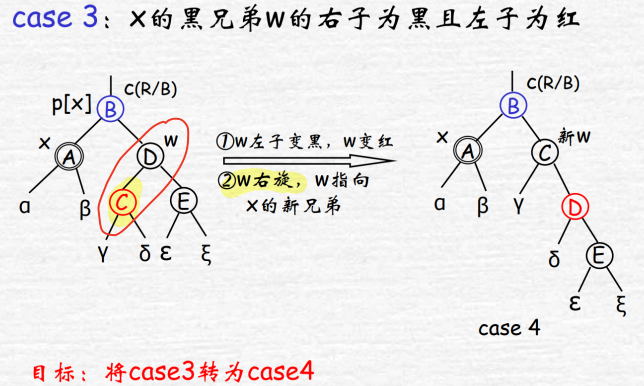
w黑且子右黑左红:将w右旋并染色,变成情况4
w黑且子右红:将父节点左旋并染色
1->2,3,4,2向上层迭代,3,4结束,最多旋转3次