
Redis线程模型
Redis基于Reactor模式开发了自己的网络事件处理器,也就是文件事件处理器。它使用IO多路复用技术,同时监听多个套接字,当套接字的可读或者可写事件触发时,就会调用相应的事件处理函数。
Redis 使用的IO多路复用技术主要有:select、epoll等,会根据不同的操作系统按不同的优先级选择。
文件事件处理器有四个组成部分:套接字、I/O多路复用程序、文件事件派发器以及事件处理器。
文件事件是对套接字操作的抽象,对应 accept、read、write、close 等操作。I/O多路复用程序负责监听多个套接字,并把产生事件的套接字传递给文件事件派发器。尽管文件事件可能并发出现,但套接字都会放到同一个队列里,然后由文件事件处理器以有序、同步方式处理,也就是处理就绪的文件事件。
Redis 6.0 之后引入多线程为了提高网络IO读写性能,因为 Redis 的瓶颈主要受限于内存和网络。但是执行命令仍然是单线程顺序执行,因此不用担心线程安全问题。
Redis为什么快
- redis数据都保存内存当中,绝大部分请求都是基于内存
- 服务器进程大部分时间是单线程操作,避免上下文切换和加锁
- 有高效的底层数据结构,为优化内存,对每种类型基本都有两种底层实现方式
- 采用的是非阻塞IO多路复用
Redis对象类型
string:二进制安全,可以存储任何类型的数据(字符串、整数、浮点数、图片、序列化对象)
- 简单动态字符串SDS
list:
- 压缩列表
- 双端链表:链表结点嵌套了字符串对象。
hash:是一个 String 类型的键值对的映射表,特别适合用于存储对象,可以直接修改对象中的字段值。
- 压缩列表:存入时将键结点、值结点依次相邻压到列表尾
- 字典:键值对直接使用字典键值对保存。
set:去重的集合
- 整数集
- 字典:将集合元素作为键,值设置为nil
zset:集合元素按 score 有序排列,还可以通过 score 的范围来获取元素的列
- 压缩列表:集合元素用相邻的节点依次保存元素成员和权重。
- 字典+跳表:字典可以实现O(1)复杂度查找,跳表可以实现范围型操作。
Redis底层数据结构
SDS
简单动态字符串常用在缓存、计数、限速等场景,底层结构包含 free、len、buf[] 字段
- len:可以获取字符串长度、防止溢出,保证二进制安全
\0 - free:预分配和惰性释放空间,可以减少修改字符串时的内存重分配
链表
用于列表键包含元素数量较多、元素都是长字符串时,双端链表,包括了头尾结点和长度
字典

用于实现map类型,由两个哈希表构成,每个哈希表里包含一个数组,数组的每个slot连接若干个哈希表结点KV
哈希算法:MurmurHash,即使输入的键规律也能得到很好的随机分布性,计算速度快
REHASH:负载因子>1且没执行bgsave或bgrewriteof || 负载因子>5:
为字典的ht[1]哈希表分配内存空间
扩展大小为首个大于
ht[0].used*2的$2^n$,收缩大小为首个大于ht[0].used的$2^n$ (便于key映射索引时用&替换%)将存储在ht[0]中的数据迁移到ht[1]上,重新计算键的哈希值和索引值。包括两种方式:渐进式HASH 和 定时HASH
清空ht[0],再交换ht[0]和ht[1]的值
渐进式HASH
增删改查操作的时候都会检查 rehashidx 参数,校验是否正在迁移,如果正在迁移那么会调用到 dictRehash(dict *d, int n) 函数。这里 n=1,即只迁移 1 个桶
- 为 ht[1] 分配空间,此时字典同时存在两个哈希表
- 将 rehashidx 置为 0,rehash 工作正式开始
- 期间每次对字典执行增删改查操作时,程序在执行指定操作之外,还会将 ht[0] 在 rehashidx 索引上的所有键值对rehash 到 ht[1],然后 rehashidx++
- 最终 ht[0] 的所有键值对最终会全部移动到 ht[1],此时程序会将 rehashidx 设为 -1表示已完成
定时HASH
主线程会默认每间隔 100ms 执行一次迁移操作,同样调用 dictRehash(dict *d, int n),这里 n=100,即迁移100个桶的数据,并限制超时时间为 1ms
REHSH期间:字典同时持有两个哈希表,此时的访问将按照如下原则处理:
- 插入键值对直接保存到ht[1]中,保证了 ht[0] 中的已经被清空的单向链表不会新增元素
- 删除、修改、查找等其他操作,会在两个哈希表上进行,即程序先尝试去ht[0]中访问要操作的数据,若不存在则到ht[1]中访问,再对访问到的数据做相应的处理。
跳跃表

跳跃表的查找复杂度为平均O(logN),最坏O(N),效率堪比红黑树但实现更简单。跳跃表是在链表的基础上,通过增加索引来提高查找效率的。
跳跃表是从有序链表中选取部分节点,组成一个新链表,并以此作为原始链表的一级索引。再从一级索引中选取部分节点,组成一个新链表,并以此作为原始链表的二级索引,以此类推。
跳跃表在查找时,优先从高层开始查找,若next节点值大于目标值或为NULL,则从当前节点下降一层继续向后查找,这样便可以提高查找的效率了。
跳表结点的底层结构包括一个元素数组、前进后退双向指针、层数(跳表查询过程中跨度)。插入跳表结点时会随机生成一个层数值以保证查询效率。
整数集合
用于保存整数值的集合,整数不重复且类型可以不同,底层结构只包括编码格式、长度、底层数组三个字段。
升级操作:由于集合中可以插入不同类型整数,当插入更长类型时会触发升级,首先将底层数组扩容到相应的大小,再依次将元素转换成新类型,最后插入新元素。
压缩列表

用于节约内存的一种线性数据结构,由一系列特殊编码的连续内存块组成,列表中可以包含多个节点,每个节点可以保存字节数组或者整数值,每个节点都有一个属性记录前一个节点的长度。
Redis持久化
RDB快照
把内存中的数据库状态以快照形式压缩保存到一个二进制文件。创建快照之后,可以对快照进行备份,可以复制到其他服务器从而创建具有相同数据的服务器副本,还可以将快照留在原地以便重启服务器的时候使用。
快照需要保存全部数据,可能导致阻塞主线程运行,redis提供了两种方式:
- save:同步保存,阻塞redis主线程
- bgsave:开一个子进程来单独生成RDB,只有fork时主进程会短暂阻塞,之后就能正常处理请求
- bgsave子进程是由主进程fork出来的:通过 fork 创建的子进程能够获得和父进程完全相同的内存空间(内存数据相同)。另外,创建子进程采用了写时拷贝,不会立刻触发大量内存的拷贝,只有父进程对内存修改时,才会复制相应的内存页
- bgsave子进程会不断读取主线程的内存数据写入RDB文件中
- 如果主线程需要修改一块数据,这块数据会被复制出一份副本,主线程在副本上修改,bgsave子进程读取原来的数据写入RDB文件
优点:生成的二进制文件体积小,恢复数据的速度非常快
缺点:bgsave需要执行fork操作创建子进程,属于重量级操作,不宜频繁执行,所以RDB无法实时持久化
AOF只追加文件
AOF日志中记录的是Redis收到的每一条命令,这些命令都是以文本的形式保存的。
写后日志
AOF先执行命令再记录日志 ①避免检查开销,后记录日志不用检查命令的正确性 ②不会阻塞当前的写操作
刷盘机制
AOF存在一定风险:如果执行完命令还没保存AOF就宕机就会数据丢失,并且写AOF可能堵塞下一个命令执行,为此AOF写入磁盘机制有三种:
- Always:每次执行完命令立即写回,基本不丢失数据
- Everysec:每次执行完命令,先把日志写入AOF缓冲区,每隔一秒刷盘,宕机也只会丢失1秒的数据
- No:只写入AOF缓冲区,由OS决定什么时候刷盘,丢失数据多
AOF重写
AOF文件越来越大,继续可能导致写入效率变低、恢复过程变长、超过文件大小限制,需要重写机制。
AOF重写就是根据所有的键值对创建一个新的AOF文件,可以减少大量的文件空间。因为AOF对于命令的添加是追加的方式,如果某个键值被反复更改会产生冗余数据,因此在重写的时候过滤掉这些指令:
- bgrewriteaof 触发重写,主进程 fork 子进程,防止主进程阻塞无法提供服务
- 子进程遍历 Redis 内存快照中数据写入临时 AOF 文件,同时会将新的写指令写入缓冲区
- 子进程写入临时 AOF 文件完成后,主进程会将缓冲区中的写指令数据写入临时 AOF 文件中
- 主进程使用临时 AOF 文件替换旧 AOF 文件,完成重写
优点:与RDB持久化可能丢失大量的数据相比,AOF持久化的安全性要高很多。使用everysec选项可以将数据丢失的时间限制在1秒之内。
缺点:AOF文件存储的是协议文本,体积更大、恢复速度更慢。AOF在进行重写时也需要创建子进程,在数据库体积较大时将占用大量资源,会导致服务器的短暂阻塞。
混合持久化
两次RDB快照期间的所有命令操作由AOF日志文件进行记录。
- RDB快照不需要很频繁的执行,可以避免频繁fork对主线程的影响,还能将丢失数据的时间限制在1s之内
- AOF日志只记录两次快照期间的操作,不用记录所有操作,防止文件过大导致重写开销
Redis数据同步
Redis其实采用了主从库的模式,以保证数据副本的一致性,主从库采用读写分离的方式:从库和主库都可以接受读操作,主库接收写操作,然后同步到从库
主从同步
第一次同步:
- 从库向主库发送 sync 命令代表进行数据同步,主库执行 bgsave 生成 RDB 文件,并发送给从库
- 从库接收数据,清空当前数据,并加载RDB文件。过程中主库不会阻塞,仍然可以接收数据,将写操作记录到
replication buffer中 - 最后,主库把
replication buffer中的修改操作发给从库,从库执行这些操作,实现主从同步 - 如果从库太多,为了减少主库过多的fork阻塞主线程,可以采用主-从-从模式,选择一个从库用来同步其他从库的数据,以减少主库生成RDB文件和传输RDB文件的压力
完成第一次同步后,双方之间就会维护一个 TCP 长连接。后续通过这个连接继续将写命令传播给从服务器,然后从服务器执行该命令,使得与主服务器的数据库状态相同。
若网络断开又恢复,会采用增量复制的方式继续同步,只会把网络断开期间主服务器的写命令同步给从服务器。
缺点:
- 没有自动容错功能,需要人工干预
- 难以在线扩容
- 主机宕机且有部分数据未同步到从库时,切换IP后会有数据不一致问题
Sentinel机制
为了解决主从模式下主库挂的问题,用哨兵机制实现主从库自动切换。哨兵是一个独立的进程,通过发送命令,等待Redis服务器响应,从而监控多个 Redis 实例。
- 监控:哨兵周期性地给所有的主从库发送 PING 命令,检测是否仍在运行。如果 Master 一段时间没有响应,这个实例会被哨兵标记为主观下线,当足够数量的哨兵确认下线时,该 Master 会被标记为客观下线
- 选主:主库挂了之后,哨兵需要按照一定的规则选择一个从库,并将他作为新的主库
- 通知:哨兵会把新主库的连接信息发给其他从库,让它们和新主库建立连接,并进行数据复制;同时哨兵也会将新主库的消息发给客户端
Redis集群
为什么要用Cluster
- 单机的CPU、内存、连接数、计算力都是有极限的,不能无限制的承载流量的扩增
- 当数据量过多的情况下,RDB持久化时响应会变慢,因为fork会阻塞主线程,数据量越大阻塞时间越长
数据分片原理
一致性哈希
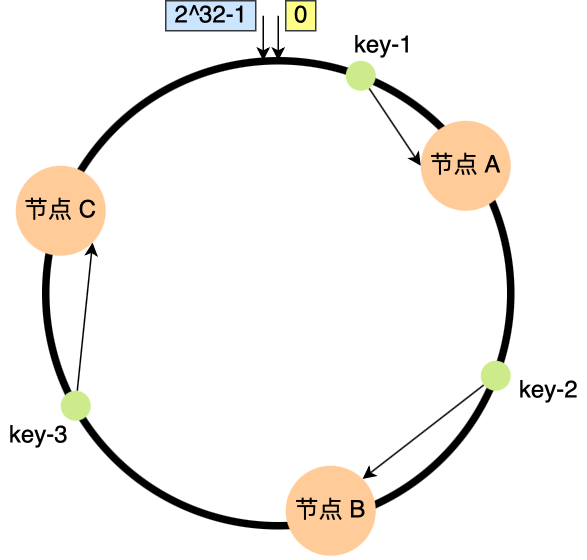
哈希算法是对节点的数量取模,而一致哈希算法是对固定的 2^32 取模,将「存储节点」和「数据」都映射到一个首尾相连的哈希环上。查找数据时,将key的映射位置往顺时针的方向的找到第一个节点,就是存储该数据的节点。
- 优点:增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
- 缺点:不保证节点能够在哈希环上分布均匀,会有大量的请求集中在一个节点上。
- 解决:将真实节点映射成多个虚拟节点,再将虚拟节点映射到哈希环上。节点数量多了后,分布就相对均匀了。
哈希槽
Redis集群将数据划分为 16384(2^14)个 slots,每个实例节点将管理其中一部分的槽位,并记录各自的槽位信息。节点的数据量可以不均匀,性能好的可以多分担一些压力。
集群之间的信息通过 Gossip协议 广播,因此每个实例都知道整个集群的 slots 分配情况以及映射信息。
每个 key 映射到一个固定的 slot,slot = crc16(key) % 16384,这样不论节点数量如何变化,key所对应的 slot 是不变的。
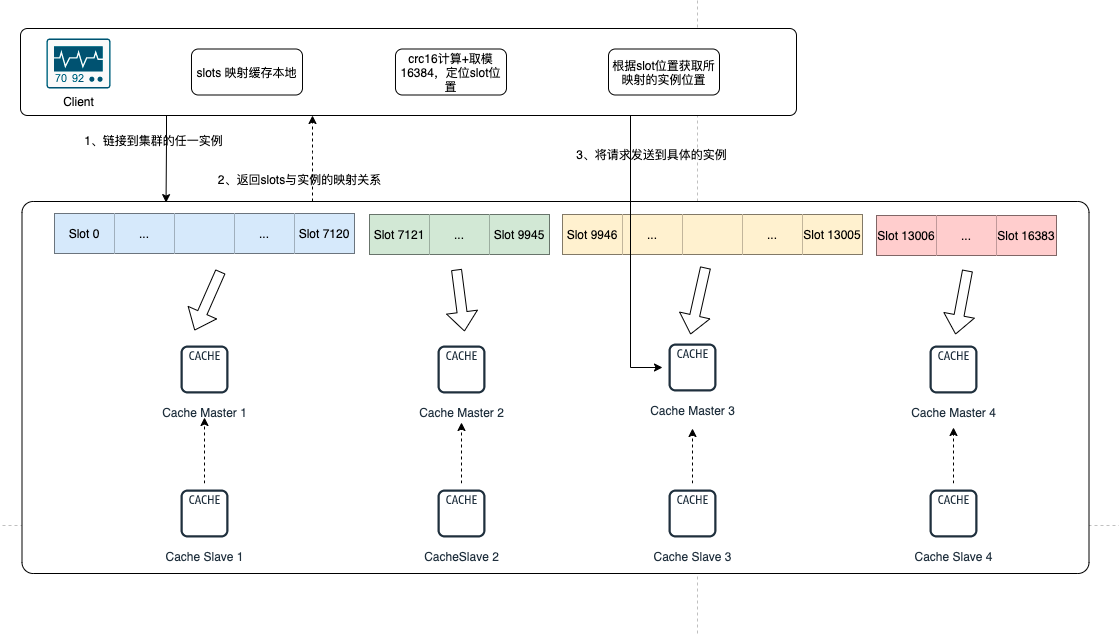
客户端访问过程:
- 连接任一实例,获取到 slots 与节点的映射关系并缓存在本地
- 对 key 经过 CRC16 计算后取模,得到 slot id
- 通过 slot id 定位到实例,发送请求
数据复制
Cluster 具备 Master 和 Slave 模式,Slave 节点是通过主从方式同步主节点数据。节点之间保持TCP通信,当Master发生了宕机, Redis Cluster 自动会将对应的 Slave 节点选为 Master,来继续提供服务。与纯主从模式不同的是,主从节点之间并没有读写分离,Slave 只用作 Master 宕机的高可用备份,所以更合理来说应该是主备模式。
故障检测与转移
Redis 集群的节点采用 Gossip 协议来广播信息,每个节点都会定期向其他节点发送 ping 命令,如果超时未回复就认为节点失联了,标记为主观下线。对于主节点A,如果超过半数主节点都将其标记为了主观下线,则标记成客观下线,并向整个集群广播节点A已经下线,开始进行主从切换:
- 如果有多个 slave 节点,先通过选举投票竞选出新的 Master
- 新的主节点将下线主节点的 slots 指派给自己
- 新的主节点向集群广播一条 PONG 消息,让其他节点知道自己变成了主节点,并且接管了下线节点负责的slots
- 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成
缓存各种问题
缓存雪崩
缓存同一时间大面积的失效,所以后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
- 设置不同的失效时间比如随机设置缓存的失效时间
缓存击穿
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据在数据库中但不在缓存中(已经过期),导致瞬时大量的请求直接打到了数据库上
- 设置热点数据永不过期或者过期时间比较长。
- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间
- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力
缓存穿透
数据库和缓存内都没有数据导致缓存永远不能命中,导致每次请求都会传到数据库加大压力。
缓存空对象:即使数据库不命中也把返回的空对象缓存起来,并设置一个较短的过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源
- 需要更多的空间存储很多空值的键
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,影响一致性
布隆过滤器:用很低的代价估算出数据是否真实存在。初始化一个大的位数组,添加key时通过不同hash计算出位数组中的不同的位置置为1;查询时检查key的hash值所对应的位点是否都被置1,若任意一个位点未被置1,则代表数据不存在,否则极有可能存在(也有可能其他的key运算导致该位为1)。
- 数据相对固定即实时性较低
数据过期策略
定期删除:默认是每隔 100ms 就随机抽取(非全表)一些设置了过期时间的key,检查如果过期就删除。定期删除可能会导致很多过期 key 到了时间并没有被删除掉
惰性删除:获取key时先判断是否过期,若过期则删除。这种策略则是会一直占用内存资源,若已经过期key未被使用,则会一直保存在内存中
内存淘汰机制:若均没被删除,内存占用越来越高
- volatile-lru、volatile-lfu、volatile-ttl、volatile-random
- allkeys-lru、allkeys-lfu、allkeys-random
- no-eviction
缓存双写一致性
先删缓存再写数据库:删完缓存、写入数据库前,另一个线程访问数据库后把旧值又写入了缓存,脏数据
先写数据库再删缓存:如果删缓存前线程崩溃,则脏数据
延时双删策略:在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。具体步骤是:
- 先删除缓存
- 再写数据库
- 休眠500毫秒(根据具体的业务时间来定)
- 再次删除缓存。
分布式锁
基于SET命令
Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:key 不存在 -> 插入成功 -> 表示加锁成功;
加锁: SET lock_key unique_value NX PX 10000
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端发生异常,导致锁无法释放,所以用 EX/PX 选项设置过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时误释放,所以用 unique_value 区分来自不同客户端的锁操作;
解锁: DEL lock_key
- 要先判断锁的 unique_value 是否为加锁客户端,是的话才删除
- 解锁有两个操作,因此需要 Lua 脚本来保证解锁的原子性
缺点
- 超时时间不好设置:太长影响性能,太短无法保护共享资源。可以基于续约的方式设置超时时间:先给锁设置一个超时时间,然后启动一个守护线程去判断锁的情况,在锁快失效时续约加锁,当主线程执行完成后
- 主从复制模式是异步复制的,导致分布式锁不可靠。如果在 Redis 主节点获取到锁后,还没同步到其他节点就宕机了,此时新的主节点依然可以获取锁,违背锁的唯一性原则。
RedLock算法
它是基于多个 Redis 节点的分布式锁,推荐至少部署 5 个 Redis 节点,它们都是主节点,之间没有任何关系。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 节点依次请求申请加锁,如果客户端能够和半数以上的节点成功地完成加锁操作,就认为客户端成功地获得分布式锁,否则加锁失败。
这样一来,即使有某个 Redis 节点发生故障,因为锁的数据在其他节点上也有保存,所以客户端仍然可以正常地进行锁操作,锁的数据也不会丢失。
加锁: 以相同的 KEY 向 N 个节点加锁,如果超过一半节点获取到了锁,且总耗时没超过锁有效时间,则认定加锁成功。之后要重新计算锁的有效时间,减去获取锁的耗时。
解锁: 向所有的节点发送 DEL 命令,和单节点一样,执行释放锁的 Lua 脚本即可。