
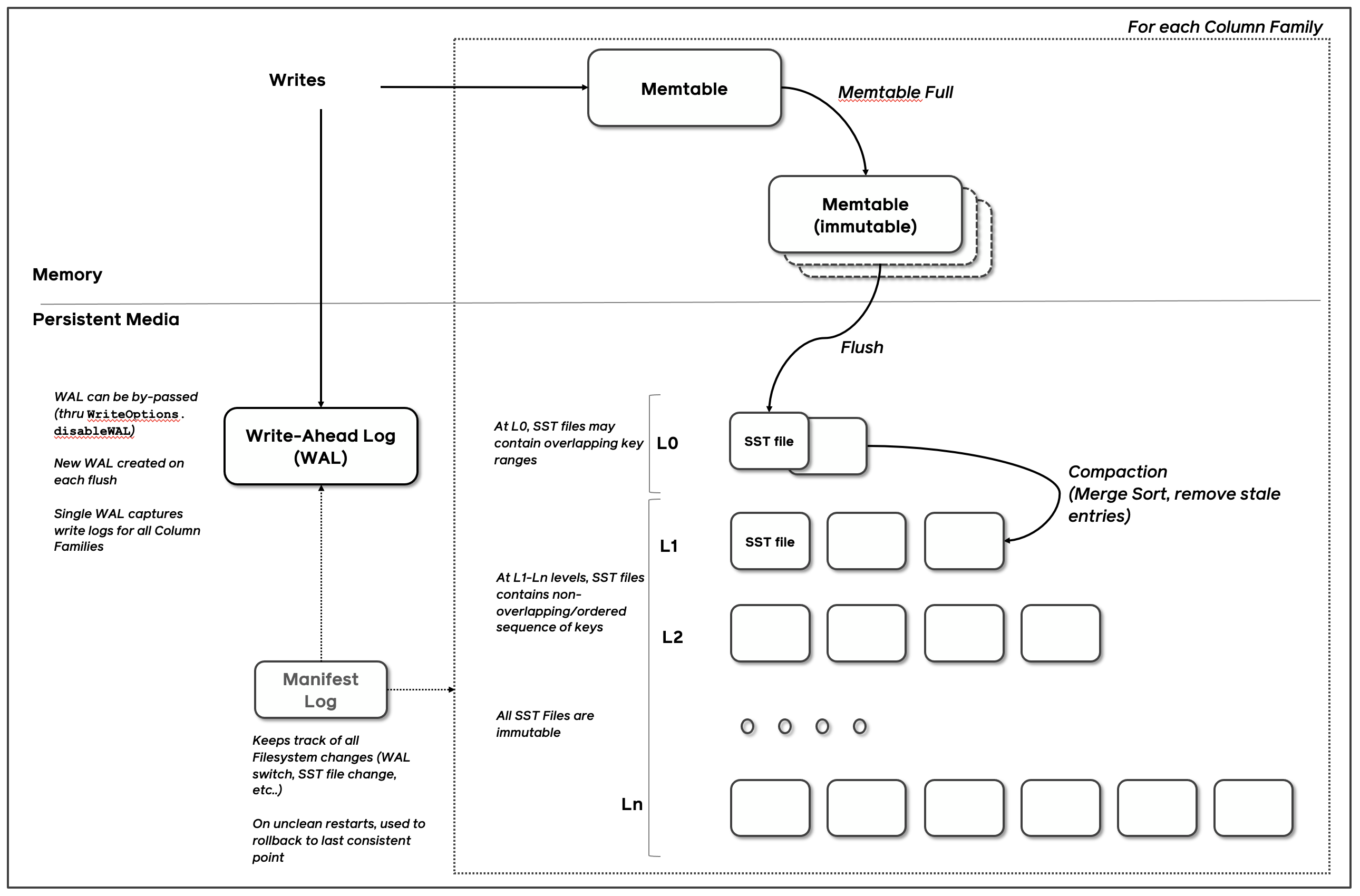
Basic Operations
Iterator
迭代器本身不会占用太多内存,但是迭代器最好保持较短的生存周期,为了确保某些资源能被释放,包括:
- 迭代器创建时的 memtables 和 SST 文件。即使某些 memtables 和 SST 文件在刷新或压缩后被删除,如果迭代器固定它们,它们仍然保留。
- 当前迭代位置的数据块。这些块将保存在内存中,要么固定在 Block Cache 中,要么在未设置块缓存时在堆中。
Iterator的创建也存在成本,因此复用iterator是最合适的,调用Iterator::Refresh() 来刷新以表示最近的状态,并且先前固定的资源会被释放。
Prefix Iterator
前缀 Iterator 是一种特殊的迭代器,允许高效地遍历具有 特定前缀 的键值对,避免遍历整个数据库,减少不必要的数据扫描,提高读取效率。
read_options.prefix_same_as_start = true,启用前缀迭代器read_options.total_order_seek,默认 false 只遍历前缀匹配的键,设置 true 会忽略前缀限制,允许迭代整个数据库(按顺序扫描所有键)
Prefix Bloom filter
前缀 Bloom Filter 是专门为 前缀迭代器 设计的,它通过将前缀与 Bloom Filter 结合,减少不必要的磁盘读取操作,加速前缀匹配的查找。
加速前缀迭代器:在进行前缀迭代时,RocksDB 会使用前缀 Bloom Filter 来判断数据是否存在于某个 SST 文件中,否则不会去读取文件。
1 | Options options; |
options.prefix_extractor指定前缀,如果这个参数改变需要重启DB,通常,最终结果是现有SST文件中的bloom过滤器在读取时会被忽略。read_options.total_order_seek = true将确保查询返回与没有前缀布隆过滤器相同的结果,忽略前缀bloom filter。read_options.auto_prefix_mode = true;防止 bloom filter 的 “假阳性” 因 hash 冲突导致的不存在的数据显示存在。
Bloom Filter
RocksDB 的每个 SST 文件都包含一个 Bloom filter。Bloom Filter 只对特定的一组 keys 有效,所以只有新的 SST 文件创建的时候才会生成这个 filter。当两个 SST 文件合并的时候,会生成新的 filter 数据。
当 SST 文件加载进内存的时候,filter 也会被加载进内存,当关闭 SST 文件的时候,filter 也会被关闭。如果想让 filter 常驻内存,可以设置BlockBasedTableOptions::cache_index_and_filter_blocks 为 true。
Compaction Filter
RocksDB提供了一种基于自定义逻辑在后台删除或修改键/值对的方法。它可以方便地实现自定义垃圾收集,比如根据TTL删除过期的键,或者在后台删除一系列键。它还可以更新现有键的值。
要使用压缩过滤器,需要实现 CompactionFilter 接口并将其设置为ColumnFamilyOptions。或者可以实现 CompactionFilterFactory` 接口,灵活地为每个(子)压缩创建不同的压缩过滤器实例。
1 | options.compaction_filter = new CustomCompactionFilter(); |
每次(子)压缩从其输入中看到一个新键,且该值是正常值时,它就调用压缩筛选器。根据压实过滤器的结果:
- 如果它决定保留key,什么都不会改变。
- 如果请求过滤键,则该值将被删除标记替换。注意,如果压缩的输出级别是底层,则不需要输出删除标记。
- 如果请求更改该值,则该值将被更改后的值替换。
- 如果它请求通过返回kRemoveAndSkipUntil来删除一段键,则压缩将跳到skip_until(意味着skip_until将是压缩后的下一个可能的键输出)。这个比较棘手,因为在这种情况下,压缩不会为它跳过的键插入删除标记。这意味着旧版本的键可能会重新出现。另一方面,如果应用程序知道没有旧版本的键,或者可以重新出现旧版本,那么简单地删除键会更有效。
如果来自压缩输入的相同键有多个版本,则对最新版本只调用压缩筛选器一次。如果最新版本是删除标记,则不会调用压缩筛选器。但是,如果删除标记没有包含在压缩的输入中,则可能对已删除的键调用压缩筛选器。
当merge被使用,每个合并操作数调用压缩过滤器。 在调用合并运算符之前,将压缩过滤器的结果应用于合并操作数。
Snapshot
快照在创建时捕获数据库的时间点视图,快照不会在数据库重新启动后持续存在。
1 | db.getSnapshot() |
快照由 SnapshotImpl 类的一个小对象表示。它只保存几个基本字段,比如快照所在的seqnum。
快照被存储在DBImpl的一个链表里。一个好处是我们可以在获取 DB 互斥锁之前分配列表节点。然后在持有互斥锁的同时,我们只需要更新列表指针。此外,可以按任意顺序对快照调用 ReleaseSnapshot()。使用链表,可以在不移动的情况下从中间删除一个节点。
在刷新/压缩期间,当我们需要找出某个键可见的最早快照时,我们必须扫描快照列表。但是链表不能二分搜索,当有很多快照时会显着降低刷新/压缩速度,导致 Write Stall。
Low Priority Write
低优先级写能够帮助用户管理写入的优先级。通过writeOptions.setLowPri(true) 设置后台写入,RocksDB将对低优先级写入进行更积极的节流,以确保高优先级写入不会 Write Stall。
如果系统认为存在压缩压力,RocksDB 会让低优先级写操作进行睡眠,降低写速率,确保高优先级写操作的处理优先级,不会因为低优先级写入过多而导致整体性能下降。
在二阶段提交过程中,低优先级写入会在准备阶段完成,而不是在提交阶段。
Column Families
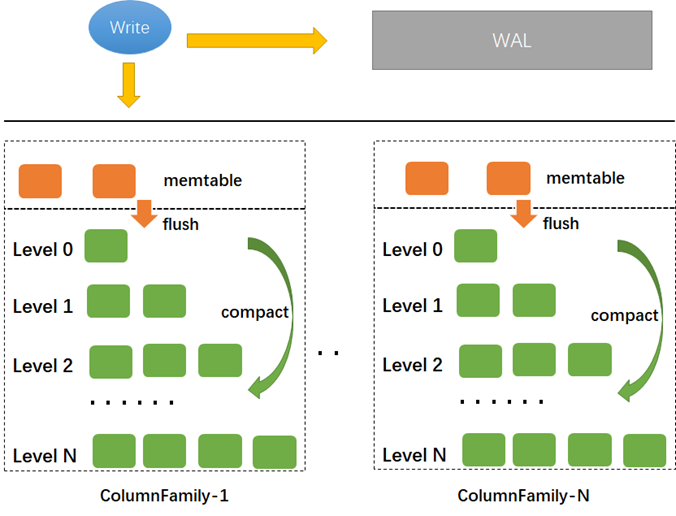
RocksDB 中的每个键值对都与一个列族相关联。 如果没有指定列族,键值对与列族 default 相关联。列族提供了一种对数据库进行逻辑分区的方法。
- 支持跨列族原子写,这个意思是可以原子写入
({cf1, key1, value1}, {cf2, key2, value2}). - 跨列族的数据库一致视图。
- 能够独立配置不同的列族。
- 即时添加新的列族并删除它们。 这两种操作都相当快。
Column Family 的思想是共享 WAL 日志而不共享 memtables 和sst 文件,即 log 共享而数据分离,可以独立配置列族并快速删除它们。
使用一个 RocksDB 就是使用一个物理存储系统,使用一个 CF 则是使用一个逻辑存储系统,二者主要区别体现在数据备份、原子写以及写性能表现上。DB 是数据备份和复制以及 checkpoint 的基本单位,但是 CF 则利用 BatchWrite,因为这个操作是可以跨 CF 的,而且多个 CF 可以共享同一个 WAL,多个 DB 则无法做到这一点。
每次 Flush 单个 CF 时,都会创建一个新的 WAL,但无法删除旧的 WAL,只有全部的列族被 Flush 且这个 WAL 包含的全部数据已经持久化时才可以删除旧的WAL文件。确保对RocksDB进行调优,以便定期刷新所有列族。另外,查看Options::max_total_wal_size,可以配置为自动刷新过时的列族。
Column Family 使用场景:
- 不同的 Column Family 可以使用不同的 setting/comparators/compression types/merge operators/compaction filters
- 对数据进行逻辑隔离,方便分别删除
- 一个 Column Family 存储 metadata,另一个存储 data;
LSM-Tree
将数据形成Log-Structured:在将数据写入LSM内存结构之前,先记录log。这样LSM就可以将有易失性的内存看做永久性存储器。并且信任内存上的数据,等到内存容量达到threshold再集体写入磁盘。
LSM 将所有数据不组织成一个整体索引结构,而组织成有序的文件集。每次LSM面对磁盘写,将数据写入一个或几个新生成的文件,顺序写入且不能修改其他文件,这样就将随机读写转换成了顺序读写。LSM将一次性集体写入的文件作为一个level,磁盘上划分多level,level与level之间互相隔离。这就形成了,以写入数据时间线形成的逻辑上、而非物理上的层级结构,这也就是为什么LSM被命名为 tree,但不是 tree。
除了将随机写合并之后转化为顺写之外,LSM 的另外一个关键特性就在于其是一种自带数据 Garbage Collect 的有序数据集合,对外只提供了 Add/Get 接口,其内部的 Compaction 就是其 GC 的关键,通过 Compaction 实现了对数据的删除、附带了 TTL 的过期数据地淘汰、同一个 Key 的多个版本 Value 地合并。RocksDB 基于 LSM 对外提供了 Add/Delete/Get 三个接口,用户则基于 RocksDB 提供的 transaction 还可以实现 Update 语义。
Checksums
Rocksdb 对每个 kv 以及整体数据文件都分别计算了 checksum,以进行数据正确性校验。下面有两个选项对 checksum 的行为进行控制。
ReadOptions::verify_checksums默认 true,强制对每次从磁盘读取的数据进行校验。Options::paranoid_checks默认 false,这个选项为 true 的时候,如果检测到内部数据部分错乱,马上抛出一个错误。
如果 RocksDB 的数据错乱,RocksDB 会尽量把它隔离出来,保证大部分数据的可用性和正确性。
Thread Pool
RocksDB 会创建一个 thread pool 与 Env 对象进行关联,线程池中线程的数目可以通过 Env::SetBackgroundThreads() 设定。通过这个线程池可以执行 compaction 与 memtable flush 任务。
当 memtable flush 和 compaction 两个任务同时执行的时候,会导致写请求被 hang 住。RocksDB 建议创建两个线程池,分别指定 HIGH 和 LOW 两个优先级。默认情况下 HIGH 线程池执行 memtable flush 任务,LOW 线程池执行 compaction 任务。
1 |
|
Setup Option
1. Write Buffer
Options::write_buffer_size是一个全局配置,应用于所有 Column Family 的默认写缓冲区。cf_options.write_buffer_size允许为每个 CF 定义不同的写缓冲区大小,从而精细化内存管理。db_options.db_write_buffer_size则影响的是数据库整体的写缓冲区大小,特别是在多 CF 的情况下,影响数据库的整体内存配置。Options::max_write_buffer_number限制了内存中可以并行存在的最大写缓冲区数量,超过将触发合并操作,默认为 2.Options::min_write_buffer_number_to_merge至少 n 个写缓冲区都填满时,才会进行合并与 Flush,防止合并操作频繁。影响了 L0 的文件个数,太小导致读放大,太大去重效果差。
Memtable 占用的空间越大,则写放大效应越小,因为数据在内存被整理好,磁盘上就越少的内容会被 compaction。Write Buffer size 并非越大越好,会导致 DB 被重新打开时的数据加载时间变长。
2. Block Cache
建议设置为总内存的 1/3 左右,剩余留给 Page Cache。所有 CF 的所有 table_options 都必须使用同一个 cache 对象,或者让所有的 DB 所有的 CF 使用同一个 table_options/table_factory。
默认 Block 的大小是 4KB,数据未经压缩。经常 bulk scan 可能需要增大 block size,单 key 读写则可能需要减小,修改方式为 Options::block_size,范围为 1KB ~ a few MB。
1 | auto cache = NewLRUCache(128 << 20); // 128MB |
3. Compression
cf_options.compression前 n-1 层压缩格式推荐 kLZ4Compression 或 kSnappyCompressioncf_options.bottommost_compression第 n 层压缩格式推荐 kZSTD 或 kZlibCompression
4. Bloom Filters
适用于大量点查如 Get(),不适合范围迭代场景 Iterator()。布隆过滤器为每个键使用一定数量的位,推荐值 10 会产生大约 1% 的假阳率。table_options.filter_policy.reset(NewBloomFilterPolicy(10, false))
5. RateLimter
设置每秒处理 request 速率:dbOptions.setRateLimiter(new RateLimiter(200))
6. Other Recommendation
1 | cf_options.level_compaction_dynamic_level_bytes = true; |
读流程
使用持久化在磁盘上不可变的 SST 文件,读路径要比写路径简单很多。要找寻某个 key,只需自顶而下遍历 LSM—Tree。从 MemTable 开始,下探到 L0,然后继续向更低层级查找,直到找到该 key 或者检查完所有 SST 文件为止。
以下是查找步骤:
- 检索 MemTable。
- 检索不可变 MemTables。
- 搜索最近 flush 过的 L0 层中的所有 SST 文件。
- 对于 L1 层及以下层级,首先找到可能包含该 key 的单个 SST 文件,然后在文件内进行搜索。
搜索 SST 文件涉及:
- (可选)探测布隆过滤器。
- 查找 index 来找到可能包含这个 key 的 block 所在位置。
- 读取 block 文件并尝试在其中找到 key。
预读取
1. 自动预读
自动预读仅适用于基于块的表格格式(Block-based table format)。这意味着它仅在 BlockBasedTableOptions 中启用了块化表格时有效。
当 RocksDB 在迭代过程中发现对同一表文件的多个顺序 I/O 请求时,它会启动自动预读机制。预读的大小从 8 KB 开始,随着每个额外的顺序 I/O 请求的出现,预读的大小呈指数增长,最大为 BlockBasedTableOptions.max_auto_readahead_size,默认最大 256 KB。
条件与限制:
- 启用条件:自动预读仅在
ReadOptions.readahead_size = 0(默认值)时启用。如果设置为其他值,则会禁用此功能。 - I/O 模式:在 Linux 系统中,自动预读在缓冲 I/O 模式下使用 readahead 系统调用,而在直接 I/O 模式下则使用 AlignedBuffer 来存储预读数据。
- 版本支持:自动迭代器预读从 RocksDB 版本 5.12 开始在缓冲 I/O 模式下支持,从 5.15 开始也支持直接 I/O 模式。
2. 手动预读控制
如果主要依赖迭代操作并且使用 Page Cache,可以通过设置 DBOptions.advise_random_on_open = false 来选择手动启用预读功能。
这种设置对硬盘驱动器(HDD)或远程存储尤为有用,尤其在这些存储的延迟较高时。对于直连的 SSD,预读对性能的影响可能不明显。
Merge
merge operator描述了原子性的在rocksdb读取修改写入操作,如果用户操作Rocksdb存在获取、修改并且再写入,那么就需要用户来保证它的原子性,merge operator可以解决这个问题。
- 将读-修改-写的语义封装到一个简单的抽象接口中。
- 允许用户避免因重复Get()调用而产生额外成本。
- 在不改变底层语义的情况下,执行后端优化以决定何时/如何组合操作数。
- 在某些情况下,可以摊销所有增量更新的成本,以提供渐进的效率提高。
MergeOperator
MergeOperator定义了几个方法来告诉RocksDB应该如何在已有的数据上做增量更新。这些方法(PartialMerge、FullMerge)可以组成新的merge操作。
AssociativeMergeOperator 接口封装了partial merge的实现细节,可以满足大部分场景的需要。使用AssociativeMergeOperator的一个前提是:数据类型的关联性,即:
- 调用Put接口写入RocksDB的数据的格式和Merge接口是相同的
- 使用用户自定义的merge操作,可以将多个merge操作数合并成一个
Generic MergeOperator 还可以用于非关联型数据类型的更新:例如,在RocksDB中保存json字符串,即Put接口写入data的格式为合法的json字符串。而Merge接口只希望更新json中的某个字段。使用场景为:
- merge 操作数的格式和Put不同
- 当多个merge操作数可以合并时,PartialMerge()方法返回true
AssociativeMergeOperator
Folding
1 | // The simpler, associative merge operator. |
用户需要定义一个子类,继承AssociativeMergeOperator,重载用到的接口。
RocksDB持有一个MergeOperator类型的成员变量,并提供了Merge接口。用户将自定义的MergeOperator子类赋值给DB对应的成员变量,这样RocksDB可以调用用户定义的Merge方法,达到用户定义merge语义的目的。
Folding
1 | // In addition to Get(), Put(), and Delete(), the DB class now also has an additional method: Merge(). |
Folding
1 | // A 'model' merge operator with uint64 addition semantics |
Generic MergeOperator
- MergeOperator提供了两个方法, FullMerge和PartialMerge. 第一个方法用于对已有的值做Put或Delete操作. 第二个方法用于在可能的情况下将两个操作数合并.
- AssociativeMergeOperator继承了MergeOperator, 并提供了这些方法的默认实现, 暴露了简化后的接口.
- MergeOperator的FullMerge方法的传入exsiting_value和一个操作数序列, 而不是单独的一个操作数.
Folding
1 | // The Merge Operator |
当调用DB::Put()和DB:Merge()接口时, 并不需要立刻计算最后的结果. RocksDB将计算的动作延后触发, 例如在下一次用户调用Get, 或者RocksDB决定做Compaction时. 所以, 当merge的动作真正开始做的时候, 可能积压(stack)了多个操作数需要处理. 这种情况就需要MergeOperator::FullMerge来对existing_value和一个操作数序列进行计算, 得到最终的值.
PartialMerge和Stacking
有时候, 在调用FullMerge之前, 可以先对某些merge操作数进行合并处理, 而不是将它们保存起来, 这就是PartialMerge的作用: 将两个操作数合并为一个, 减少FullMerge的工作量.
当遇到两个merge操作数时, RocksDB总是先会尝试调用用户的PartialMerge方法来做合并, 如果PartialMerge返回false才会保存操作数. 当遇到Put/Delete操作, 就会调用FullMerge将已存在的值和操作数序列传入, 计算出最终的值.
Compaction
Leveled Compaction 流程大致为:
- 找到 score 最高的 level
- 根据一定策略从 level 中选择一个 sst 文件进行 compact,L0 的各个 sst 文件之间 key 有重叠,所以可能一次选取多个
- 获取 sst 文件的 minkey 和 maxkey
- 从 level + 1 中选取出于 (minkey, maxkey) 有重叠的 sst 文件,与 level 中的文件进行
merge - sort作为目标文件,没有重叠文件则把原始文件作为目标文件 - 对目标文件进行压缩后放入 level + 1 中
L0 subcompaction
参数 maxbackgroundcompactions 大于 1 时,RocksDB 会进行并行 Compact,但 L0 到 L1 层的 Compaction 任务不能进行并行,这会约束整体 compaction 速度。可以设置 max_subcompactions 参数大于 1,尝试把一个文件拆为多个 sub,启动多个线程执行 sub-compact。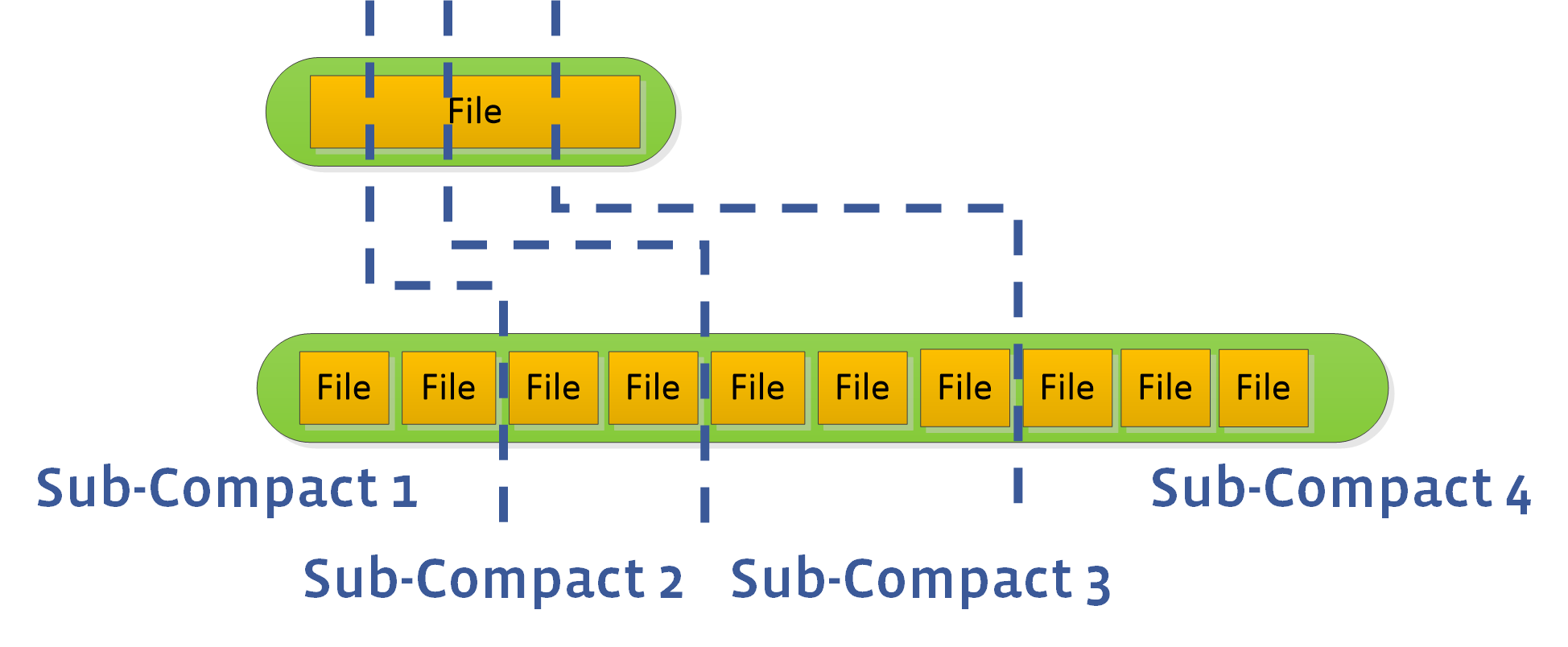
Compaction的选择策略
当多个level都满足触发compaction的条件,rocksdb通过计算得分来选择先做哪一个level的compaction。
- 对于非0 level,score =
该level文件的总长度 / 阈值。已经正在做compaction的文件不计入总长度中。 - 对于L0,score =
max{文件数量 / level0_file_num_compaction_trigger, L0文件总长度 / max_bytes_for_level_base}并且L0文件数量 > level0_file_num_compaction_trigger。
Compaction触发阈值
每一层的compaction阈值设置策略由 level_compaction_dynamic_level_bytes 来决定。
当 level_compaction_dynamic_level_bytes 为 false:
- L1 触发阈值:max_bytes_for_level_base
- 下面的level触发阈值通过公式计算:Target_Size(Ln+1) = Target_Size(Ln) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_additional[n].max_bytes_for_level_multiplier_additional
max_bytes_for_level_base = 16384
max_bytes_for_level_multiplier = 10
max_bytes_for_level_multiplier_additional = 1
那么每个level的触发阈值为 L1, L2, L3 and L4 分别为 16384, 163840, 1638400 和 16384000
当 level_compaction_dynamic_level_bytes 为 true:
- 最后一个level的文件长度总是固定的。
- 上面level触发阈值通过公式计算:Target_Size(Ln-1) = Target_Size(Ln) / max_bytes_for_level_multiplier。如果计算得到的值小于 max_bytes_for_level_base / max_bytes_for_level_multiplier, 那么该level将维持为空,L0做compaction时将直接merge到第一个有合法阈值的level上。
max_bytes_for_level_base = 1G
num_levels = 6
level 6 size = 276G
那么从L1到L6的触发阈值分别为:0, 0, 0.276G, 2.76G, 27.6G,276G。
这样分配保证了稳定的 LSM-tree 结构。并且有 90% 的数据在最后一层,9%的数据在倒数第二层

Blob
blob_db参考了WiscKey的思想,设计的kv存储分离,可以有效的减小写放大。
LSM树里面只存储key和value的地址,这样后台线程compact的时候可以少读写很多数据。
rocksdb里面增加一种类型:kTypeBlobIndex 表示value是否blob_db的地址。
写流程
首先判断value大小是否超过配置,超过了就写blob_db,然后在把offset和文件id做为value写入lsm树。
否则就是正常的rocksdb写入。如果设置了db最大size,并且磁盘空间超过限制了,就会淘汰删除最老的blob文件。
blob文件格式:
head结构
|—-|—-|—-|-|-|——–|———|
magic version cf_id flag expiration_start expiration_end
foot结构
|—-|——–|——–|———|—-|
magic count expiration_start expiration_end crc
和sst文件一样,blob文件写完以后,不会被更改,只能被删除。
每个blob文件都有size限制,超过这个限制就会和wal一样,重新打开一个blob文件写入。
每个blob文件没有类似rocksdb那样的level层级。
读流程
主要的流程还是和普通的db一样,增加GetImplOptions里面is_blob_index选项。
BlobDBOptions选项里面min_blob_size控制多大的value存储在blob_db中,小于min_blob_size,还是和原来一样,存储在lsm树。
根据返回的value类型判断,如果是kTypeBlobIndex,那么就需要再从blob_db获取真正的value,可以看到比原来多了一次读。
先需要解码lsm树里面获取的value,找到对应的blob_db里面的文件和offset,然后再获取真正的数据。
GC流程
每个blob文件或者会有几个对应的sst文件,或者对应几个memtable。
只有blob文件没有关联的sst文件并且blob文件的seq比flush_seq大,才满足被gc删除条件。
后台线程会周期性的删除无用的blob文件。
Flush memtable的时候会跟进value类型判断,如果valuekTypeBlobIndex,则会更新文件对应的最早的blob文件。
Flush完成以后会调用blob的回调函数,建立新的sst文件和blob文件的对应关系。
Compact完成以后也会调用blob的回调函数,老的sst文件和blob文件映射关系解除,增加新的sst文件和blob文件的映射关系。
内存结构
RocksDB的内存大致有如下四个区:
- Block Cache
- Indexes and bloom filters
- Memtables
- Blocked pinned by iterators
Block Cache
在内存中缓存数据用于读取。一个Cache对象可以在同一个进程中被多个 DB 实例共享,从而允许用户控制整个缓存容量。Block Cache 存储未压缩的块,用户可以选择设置第二个 Block Cache 存储压缩块。先读取未压缩的块,再读取压缩的块。如果使用Direct-IO,压缩块缓存可以替代 Page cache。
RocksDB 中有两种缓存实现,分别是 LRUCache 和 ClockCache。两种类型的缓存都被分片以减轻锁争用。默认每个缓存将被分片为最多 64 个分片,每个分片的容量不低于 512k 字节。
Indexes and bloom filters
Index 由 key、offset 和 size 三部分构成,通常仅索引每个 Block 中的第一个 key(或者是一个代表性的 key)。当 Block Cache 增大 Block Size 时,block 个数必会减小,index 个数也会随之降低,如果减小 key size,index 占用内存空间的量也会随之降低。
filter是 bloom filter 的实现,如果缩小 bloom 占用的空间,可以设置 options.optimize_filters_for_hits = true,则最后一个 level 的 filter 会被关闭,bloom 占用率只会用到原来的 10% 。
默认情况下 index 和 filter block 与 block cache 是独立的,用户不能设定二者的内存空间使用量,但为了控制 RocksDB 的内存空间使用量,可以设置 cache_index_and_filter_blocks = true,将 index & filter 存入 block cache。
需要注意的是,index 与 filter 一般访问频次比 data 高,所以把他们放到一起会导致内存空间与 cpu 资源竞争,进而导致 cache 性能抖动厉害。有两个优化方式:
cache_index_and_filter_blocks_with_high_priority = true和high_pri_pool_ratio = 0.8,会把 LRU Cache 划分为高低优先级的两个区域,data 放在 low 区,index 和 filter 放在 high 区,如果高区占用的内存空间超过了 80%,则会侵占 low 区的尾部数据空间。pin_l0_filter_and_index_blocks_in_cache设为 true,把 level0 的 index 以及 filter block 放到 Block Cache 中,因为 l0 访问频次最高,一般内存容量不大,占用不了多大内存空间。
如果 cache_index_and_filter_blocks = false(默认值),index/filter 个数就会受 max_open_files 影响,官方建议把这个选项设置为 -1,以方便 RocksDB 加载所有的 index 和 filter 文件,最大化程序性能。
Memory pool
不管 RocksDB 有多少 column family,一个 DB 只有一个 WriteController,一旦 DB 中一个 column family 发生堵塞,那么就会阻塞其他 column family 的写。RocksDB 写入时间长了以后,可能会不定时出现较大的写毛刺,可能有两个地方导致 RocksDB 会出现较大的写延时:
- 获取 mutex 时可能出现几十毫秒延迟:因为 flush/compact 线程与读写线程竞争导致的,可以通过调整线程数量降低毛刺时间。
- 数据写入 memtable 时候可能出现几百毫秒延时:解决方法一就是使用大的 page cache,禁用系统 swap 以及配置 min_free_kbytes、dirty_ratio、dirty_background_ratio 等参数来调整系统的内存回收策略,更基础的方法是使用内存池。
采用内存池时,memtable 的内存分配和回收流程图如下: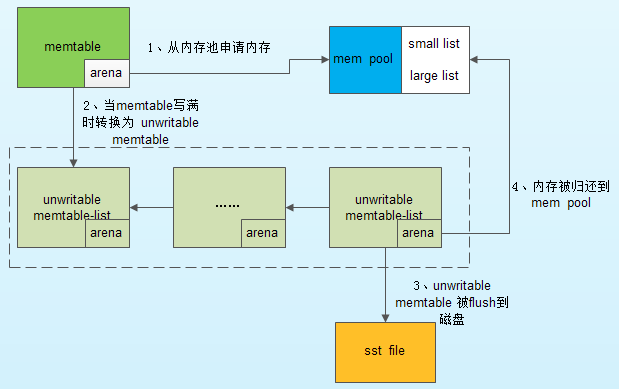
磁盘结构
RocksDB 磁盘上的数据种类:
- DB 的操作日志
- 存储实际数据的 SSTable 文件
- DB 的元信息 Manifest 文件
- 记录当前正在使用的 Manifest 文件,它的内容就是当前的 Manifest 文件名
- 系统的运行日志,记录系统的运行信息或者错误日志
- 临时数据库文件,repair 时临时生成的
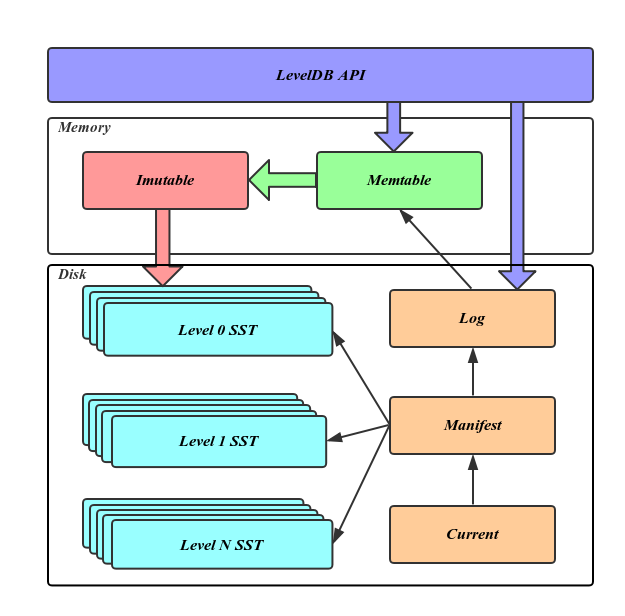
Write Ahead Log

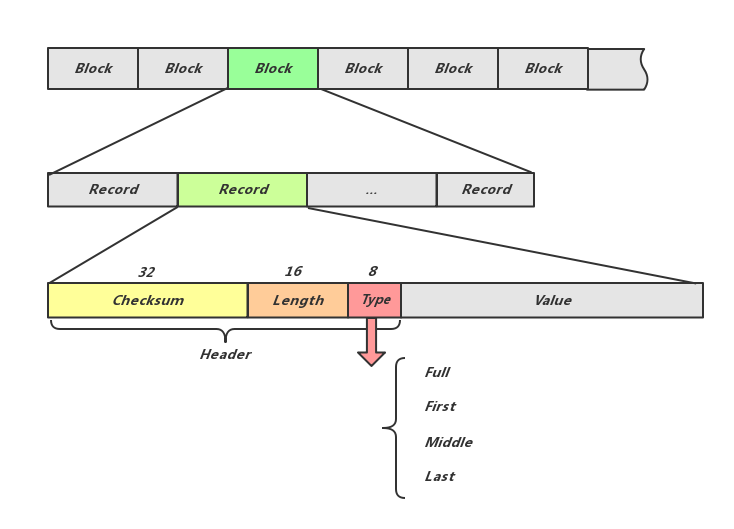
如上图,log 文件的逻辑单位是 Record,物理单位是 block,每个 Record 可以存在于一个 block 中,也可以占用多个 block。Record 的详细结构见上图文字部分,其 type 字段的意义见下图,如果某 KV 过长则可以用多 Record 存储。
Manifest
MANIFEST是指在事务日志中跟踪 RocksDB 状态变化的系统Manifest-<seq no>是指包含 RocksDB 状态快照/编辑的单个日志文件CURRENT是指当前最新的 mainfest log
RocksDB 是文件系统和存储介质无关的。文件系统操作不是原子操作,在系统故障时很容易出现不一致。即使打开了日志记录,文件系统也不能保证不干净重启时的一致性,POSIX 文件系统也不支持原子批处理操作。为了避免进程崩溃或机器宕机导致的数据丢失,RocksDB 需要将元信息数据持久化到磁盘,承担这个任务的就是 Manifest 文件,每当有新的Version产生都需要更新 Manifest。
Manifest 文件记录了 DB 状态变化的事务性日志,即所有改变 DB 状态的操作。任意时间存储引擎的状态都会保存为一个Version(即SST的集合),而每次对 Version 的修改都是一个VersionEdit,而最终这些 VersionEdit 就是组成 Manifest 文件的内容。在 Manifest 中的一次增量内容称作一个Block,Manifest Block 的详细结构如下图所示:
RocksDB 进程 Crash 后 Reboot 的过程中,会首先读取 Manifest 文件在内存中重建 LSM 树,然后根据 WAL 日志文件恢复 Memtable 内容。
下图是 leveldb 的 Manifest 文件结构,这个 Manifest 文件有以下文件内容: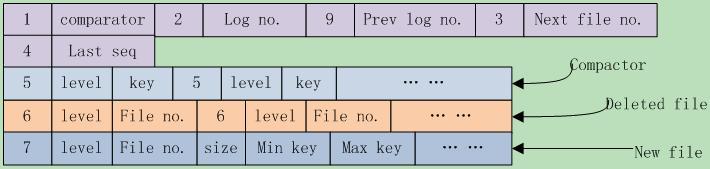
VersionSet
VersionSet 是 RocksDB 用于管理数据库版本和存储布局的核心结构。它包含了关于当前数据库版本的信息,以及该版本所包含的 SST 文件、ColumnFamily、memtable 等的状态信息。
RocksDB 的 Version 表示一个版本的 metadata,其主要内容是 FileMetaData 指针的二维数组,分层记录了所有的SST文件信息。FileMetaData 用来维护一个文件的元信息,包括文件大小、文件编号、最大最小值、引用计数等信息,其中引用计数记录了被不同的 Version 引用的个数,保证被引用中的文件不会被删除。
Version中还记录了触发 Compaction 相关的状态信息,这些信息会在读写请求或 Compaction 过程中被更新。在 CompactMemTable 和 BackgroundCompaction 过程中会导致新文件的产生和旧文件的删除,每当这个时候都会有一个新的对应的 Version 生成,并插入 VersionSet 链表头部,LevelDB 用 VersionEdit 来表示这种相邻 Version 的差值。
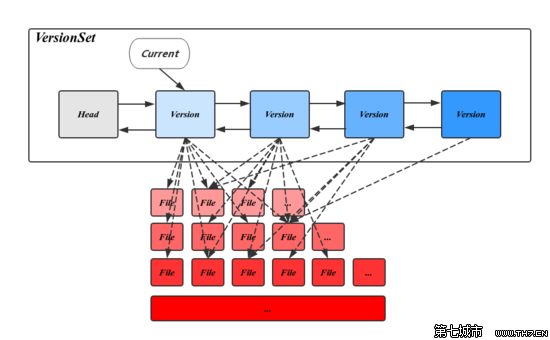
VersionSet 结构如上图所示,它是一个 Version 构成的双向链表,这些 Version 按时间顺序先后产生,记录了当时的元信息,链表头指向当前最新的 Version,同时维护了每个 Version 的引用计数,被引用中的 Version 不会被删除,其对应的 SST 文件也因此得以保留,通过这种方式,使得LevelDB 可以在一个稳定的快照视图上访问文件。VersionSet 中除 Version 的双向链表外还会记录一些如 LogNumber、Sequence、下一个SST文件编号的状态信息。
MetaData Restore
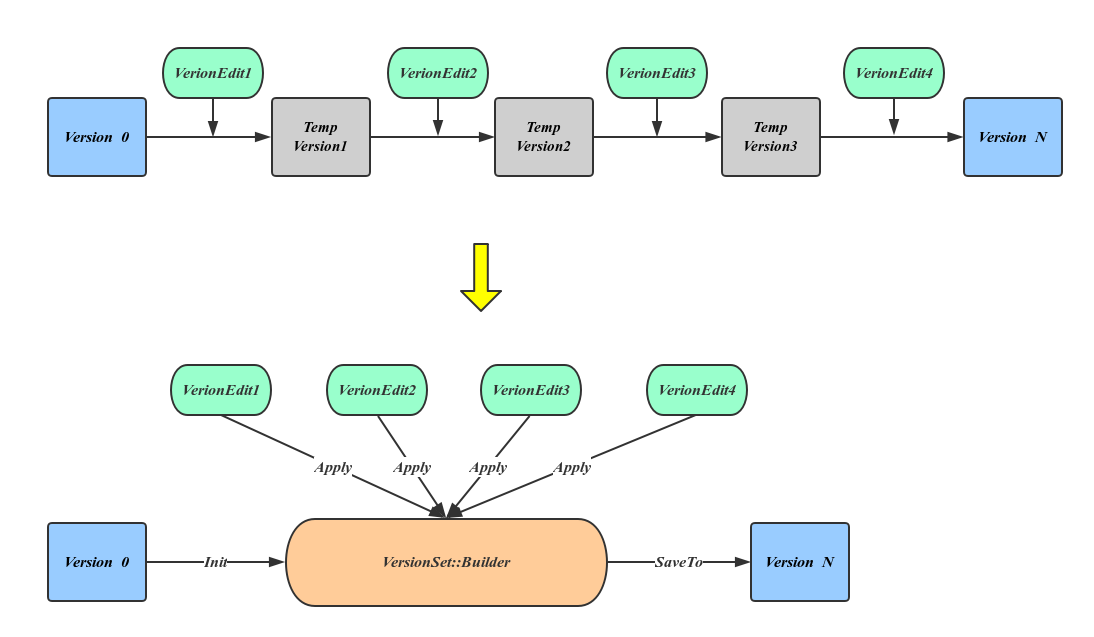
上图最上面的流程显示了恢复元信息的过程,也就是一次应用 VersionEdit 的过程,这个过程会有大量的临时 Version 产生,但这种方法显然太过于耗费资源,LevelDB 引入 VersionSet::Builder 来避免这种中间变量,方法是先将所有的 VersoinEdit 内容整理到 VersionBuilder 中,然后一次应用产生最终的 Version,如上图下部分所示。
数据恢复的详细流程如下:
- 依次读取Manifest文件中的每一个Block,将从文件中读出的 Record 反序列化为 VersionEdit;
- 将每一个的 VersionEdit Apply 到
VersionSet::Builder中,进而生成Version; - 计算compactionlevel、compactionscore;
- 将新生成的 Version 挂到 VersionSet 中,并初始化 VersionSet 的 manifestfilenumber,nextfilenumber,lastsequence,lognumber,prevlognumber 信息;
SST file
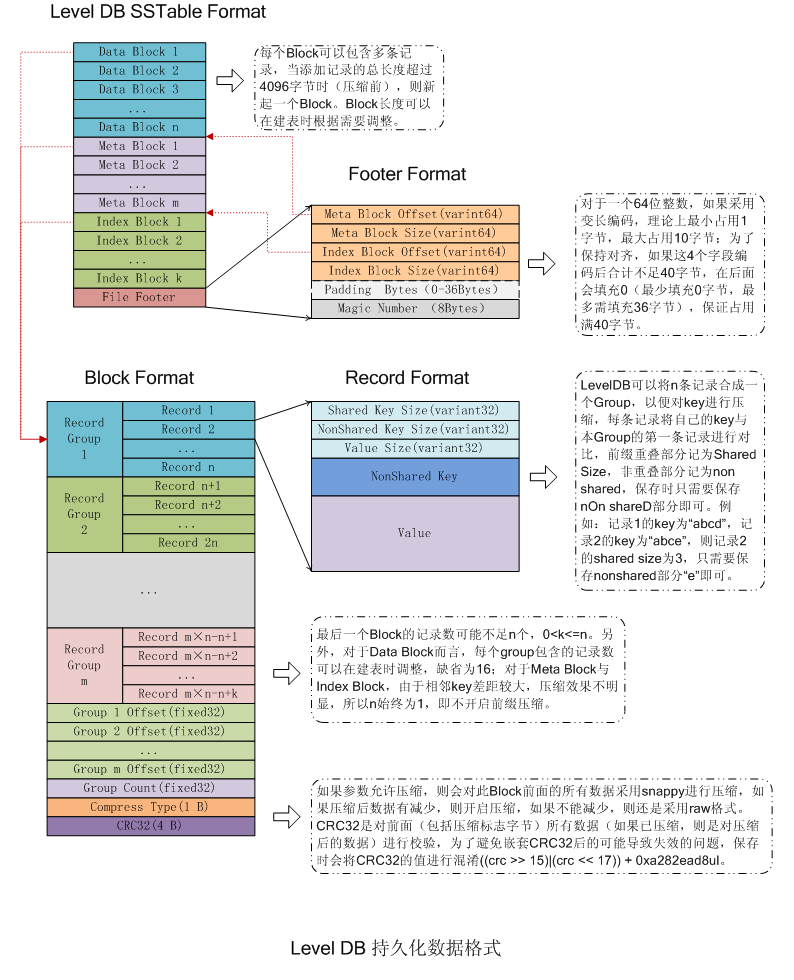
SSTfile 结构如下,大致分为几个部分:
- Data Block 直接存储有序键值对,是 SSTfile 的数据实体
- Meta Block 存储 Filter 相关信息
- Meta Index Block 是 Meta Block 的索引,它只有一条记录
- Index Block 是 Key 到 Data Block 的索引,是提高查询效率的关键
- Footer 指向各个分区的位置和大小
1 | <beginning_of_file> |
RocksDB 执行查询或修改时会引用当前 version,对该 version 下的 sst file 设置 reference count,Compact完成后要等 reference count 降为 0 后才能将文件真正的删除。
Block结构如下图:
Record 结构如下图:
Footer 结构如下图:
Memtable
Memtable 中存储了一些 metadata 和 data,data 在 skiplist 中存储。metadata 数据如下:
- 当前日志句柄;
- 版本管理器、当前的版本信息(对应 compaction)和对应的持久化文件标示;
- 当前的全部db配置信息比如 comparator 及其对应的 memtable 指针;
- 当前的状态信息以决定是否需要持久化 memtable 和合并 sstable;
- sstable 文件集合的信息。
Snapshot
RocksDB 每次进行更新操作就会把更新内容写入 Manifest 文件,同时它会更新版本号。
版本号是一个 8 字节的证书,每个 key 更新时,除了新数据被写入数据文件,同时记录下 RocksDB 的版本号。RocksDB 的 Snapshot 数据仅仅是逻辑数据,并没有对应的真实存在的物理数据,仅仅对应一下当前 RocksDB 的全局版本号而已,只要 Snapshot 存在,每个 key 对应版本号的数据在后面的更新、删除、合并时会一并存在,不会被删除,以保证数据一致性。
Checkpoints
Checkpoints 是 RocksDB 提供的一种 snapshot,独立的存在一个单独的不同于 RocksDB 自身数据目录的目录中,既可以 ReadOnly 模式打开,也可以 Read-Write 模式打开。Checkpoints 被用于全量或者增量 Backup 机制中。
如果 Checkpoints 目录和 RocksDB 数据目录在同一个文件系统上,则 Checkpoints 目录下的 SST 是一个 hard link(SST 文件是 Read-Only的),而 manifest 和 CURRENT 两个文件则会被拷贝出来。如果 DB 有多个 Column Family,wal 文件也会被复制,其时间范围足以覆盖 Checkpoints 的起始和结束,以保证数据一致性。
如果以 Read-Write 模式打开 Checkpoints 文件,则其中过时的 SST 文件会被删除掉。
Backup
RocksDB 提供了 point-of-time 数据备份功能,可以调用 BackupEngine::CreateNewBackup(db, flush_before_backup = false) 接口进行数据备份, 其大致流程如下:
- 禁止删除文件(sst 文件和 log 文件);
- 调用 GetLiveFiles() 获取当前的有效文件,如 table files, current, options and manifest file;
- 将 RocksDB 中的所有的 sst/Manifest/配置/CURRENT 等有效文件备份到指定目录;GetLiveFiles() 接口返回的 SST 文件如果已经被备份过,则这个文件不会被重新复制到目标备份目录,但是 BackupEngine 会对这个文件进行 checksum 校验,如果校验失败则会中止备份过程。
- 如果 flush_before_backup 为 false,则BackupEngine 会调用 GetSortedWalFiles() 接口把当前有效的 wal 文件也拷贝到备份目录;
- 重新允许删除文件。
sst 文件只有在 compact 时才会被删除,所以禁止删除就相当于禁止了 compaction。别的 RocksDB 在获取这些备份数据文件后会依据 Manifest 文件重构 LSM 结构的同时,也能恢复出 WAL 文件,进而重构出当时的 memtable 文件。
在进行 Backup 的过程中,写操作是不会被阻塞的,所以 WAL 文件内容会在 backup 过程中发生改变。RocksDB 的 flushbeforebackup 选项用来控制在 backup 时是否也拷贝 WAL,其值为 true 则不拷贝。
Snapshot 仅仅存在于逻辑概念上,其对应的实际物理文件可能正被 compaction 线程执行写任务;
Checkpoint 则是实际物理文件的一个镜像,或者说是一个硬链接,而出处于同样的 Env 下(都是 RocksDB 数据文件格式);
Backup 虽然也是物理数据的镜像,但是与原始数据处于不同的 Env 下(如 backup 可能在 HDFS 上);
调优配置
如何保证数据快速写入RocksDb
- 使用单个写入线程并且有序插入
- 将数百个键批量写入一批
- memtable底层数据结构使用vector
- 确保
options.max_background_flushes至少为4 - 在插入数据之前,禁用自动压缩,将 options.level0_file_num_compaction_trigger、options.level0_slowdown_writes_trigger 和 options.level0_stop_writes_trigger 设置为非常大的值。插入所有数据后,发出手动压缩。如果调用了Options::PrepareForBulkLoad(),后面三个方法会被自动启用;
- 可以通过
SstFileWriter直接创建 SST 文件并添加到 RocksDB 中。但是它的键范围一定不能与数据库重叠。
WriteStall触发场景
当RocksDB的flush或compact 速度落后于数据写入速度就会增加空间放大和读放大,可能导致磁盘空间被撑满或严重的读性能下降,为此则需要限制数据写入速度或者完全停止写入,这个限制就是write stall,触发原因有三个:
1. memtable数量过多
- 当memtable数量达到min-write-buffer-number-to-merge (默认值为1) 参数个时会触发flush,Flush慢主要由于磁盘性能问题引起
- 当等待flush的memetable数量达到参数max-write-buffer-number时会完全停止写入。当max-write-buffer-number>3且等待flush的memetable数量>=参数max-write-buffer-number-1时会降低写入速度。
- 当由于memtable数量引起write stall时,内存充足的情况下可尝试调大max-write-buffer-number、max_background_jobs 、write_buffer_size 进行缓解。
2. L0数量过多
- 当L0 sst文件数达到level0_slowdown_writes_trigger后会触发write stall 降低写入速度,当达到level0_stop_writes_trigger则完全停止写入。
- 当由于memtable数量引起write stall时,内存充足的情况下可尝试调大max_background_jobs 、write_buffer_size、min-write-buffer-number-to-merge进行缓解。
3. 待compact的数据量过多
- 当需要compact的文件数量达到soft_pending_compaction_byte参数值时会触发write stall,降低写入速度,当达到hard_pending_compaction_byte时会完全停止写入.
FAQ
- 如果机器崩溃后重启,则 RocksDB 能够恢复的数据是同步写【WriteOptions.sync=true】调用 DB::SyncWAL() 之前的数据 或者已经被写入 L0 的 memtable 的数据都是安全的;
- 可以通过 GetIntProperty(cf_handle, “rocksdb.estimate-num-keys”) 获取一个 column family 中大概的 key 的个数;
- 可以通过 GetAggregatedIntProperty(“rocksdb.estimate-num-keys”, &num_keys) 获取整个 RocksDB 中大概的 key 的总数,之所以只能获取一个大概数值是因为 RocksDB 的磁盘文件有重复 key,而且 compact 的时候会进行 key 的淘汰,所以无法精确获取;
- 当进程中还有线程在对 RocksDB 进行 读、写或者手工 compaction 的时候,不能强行关闭它;
- 关闭 RocksDB 对象时,如果是通过 DestroyDB() 去关闭时,这个 RocksDB 还正被另一个进程访问,则会造成不可预料的后果;
- 当 BackupOptions::backup_log_files 或者 flush_before_backup 的值为 true 的时候,如果程序调用 CreateNewBackup() 则 RocksDB 会创建 point-in-time snapshot,RocksDB进行数据备份的时候不会影响正常的读写逻辑;
- RocksDB 启动之后不能修改 prefix extractor;
- SstFileWriter API 可以用来创建 SST 文件,如果这些 SST 文件被添加到别的 RocksDB 数据库发生 key range 重叠,则会导致数据错乱;
- 使用多磁盘时,RAID 的 stripe size 不能小于 64kb,推荐使用1MB;
- RocksDB 可以针对每个 SST 文件通过 ColumnFamilyOptions::bottommost_compression 使用不同的压缩的方法;
- 当多个 Handle 指向同一个 Column Family 时,其中一个线程通过 DropColumnFamily() 删除一个 CF 的时候,其引用计数会减一,直至为 0 时整个 CF 会被删除;
- RocksDB 接受一个写请求的时候,可能因为 compact 会导致 RocksDB 多次读取数据文件进行数据合并操作;
- RocksDB 不直接支持数据的复制,但是提供了 API GetUpdatesSince() 供用户调用以获取某个时间点以后更新的 kv;
- options.prefixextractor 一旦启用,就无法继续使用 Prev() 和 SeekToLast() 两个 API,可以把 ReadOptions.totalorder_seek 设置为 true,以禁用 prefix iterating;
- 当 BlockBaseTableOptions::cache_index_and_filter_blocks 的值为 true 时,在进行 Get() 调用的时候相应数据的 bloom filter 和 index block 会被放进 LRU cache 中,如果这个参数为 false 则只有 memtable 的 index 和 bloom filter 会被放进内存中;
- 当调用 Put() 或者 Write() 时参数 WriteOptions.sync 的值为 true,则本次写以前的所有 WriteOptions.disableWAL 为 false 的写的内容都会被固化到磁盘上;
- 禁用 WAL 时,DB::Flush() 只对单个 Column Family 的数据固化操作是原子的,对多个 Column Family 的数据操作则不是原子的,官方考虑将来会支持这个 feature;
- 当使用自定义的 comparators 或者 merge operators 时,ldb 工具就无法读取 sst 文件数据;
- RocksDB 执行前台的 Get() 和 Write() 任务遇到错误时,它会返回 rocksdb::IOError 具体值;
- RocksDB 执行后台任务遇到错误时 且 options.paranoid_checks 值为 true,则 RocksDB 会自动进入只读模式;
- RocksDB 一个线程执行 compact 的时候,这个任务是不可取消的,可以在另一个线程调用 CancelAllBackgroundWork(db, true) 以中断正在执行的 compact 任务;
- 当多个进程打开一个 RocksDB 时,如果指定的 compact 方式不一样,则后面的进程会打开失败;
- RocksDB 不支持多列;
- RocksDB 的读并不是无锁的,有如下情况:(1) 访问 sharded block cache (2) 如果 table cache options.maxopenfiles 不等于 -1 (3) 如果 flush 或者 compaction 刚刚完成,RocksDB 此时会使用全局 mutex lock 以获取 LSM 树的最新 metadata (4) RocksDB 使用的内存分配器如 jemalloc 有时也会加锁,这四种情况总体很少发生,总体可以认为读是无锁的;
- 如果想高效的对所有数据进行 iterate,则可以创建 snapshot 然后再遍历;
- 如果一个 key space range (minkey, maxkey) 很大,则使用 Column Family 对其进行 sharding,如果这个 range 不大则不要单独使用一个 Column Family;
- RocksDB 没有进行 compaction 的时候,可以通过 rocksdb.estimate-live-data-size 可以估算 RocksDB 使用的磁盘空间;
- 即使没有被标记为删除的 key,也没有数据过期,RocksDB 仍然会执行 compaction,以提高读性能;
- RocksDB 的 key 和 value 是存在一起的,遍历一个 key 的时候,RocksDB 已经把其 value 读入 cache 中;
- 对于一个离线 DB 可以通过 sstdump –showproperties –command=none 命令获取特定 sst 文件的 index & filter 的 size,对于正在运行的 DB 可以通过读取 DB 的属性 kAggregatedTableProperties 或者调用 DB::GetPropertiesOfAllTables() 获取 DB 的 index & filter 的 size。