GFS的产生背景
GFS是Google针对其数据访问量和应用场景而设计的分布式存储系统,其特点:
- 数据量大:海量数据,大文件为主,每个文件有几百MB,甚至几GB大小。系统支持小文件,但不需要针对小文件做专门的优化。
- 数据访问的特点是做数据分析:因此,顺序访问比较多,需要顺序遍历数据文件,大规模的流式读取数据。
- 写操作以高效且原子性的追加写操作,文件多用于生产者-消费者模型,或多路归并操作。数据一旦被写入之后,文件就很少再被修改。
- 高性能的网络带宽远比低延时重要。因为,大部分情况下要求能够高效率、大批量地处理数据,对单一的读写操作的时间响应要求较低。
- 系统由廉价的普通机器硬件组成,因此,节点失效是常态,GFS必须有较高的容错性,能够持续监控自身的状态,还能从节点失效导致的异常中快速恢复。
GFS的架构
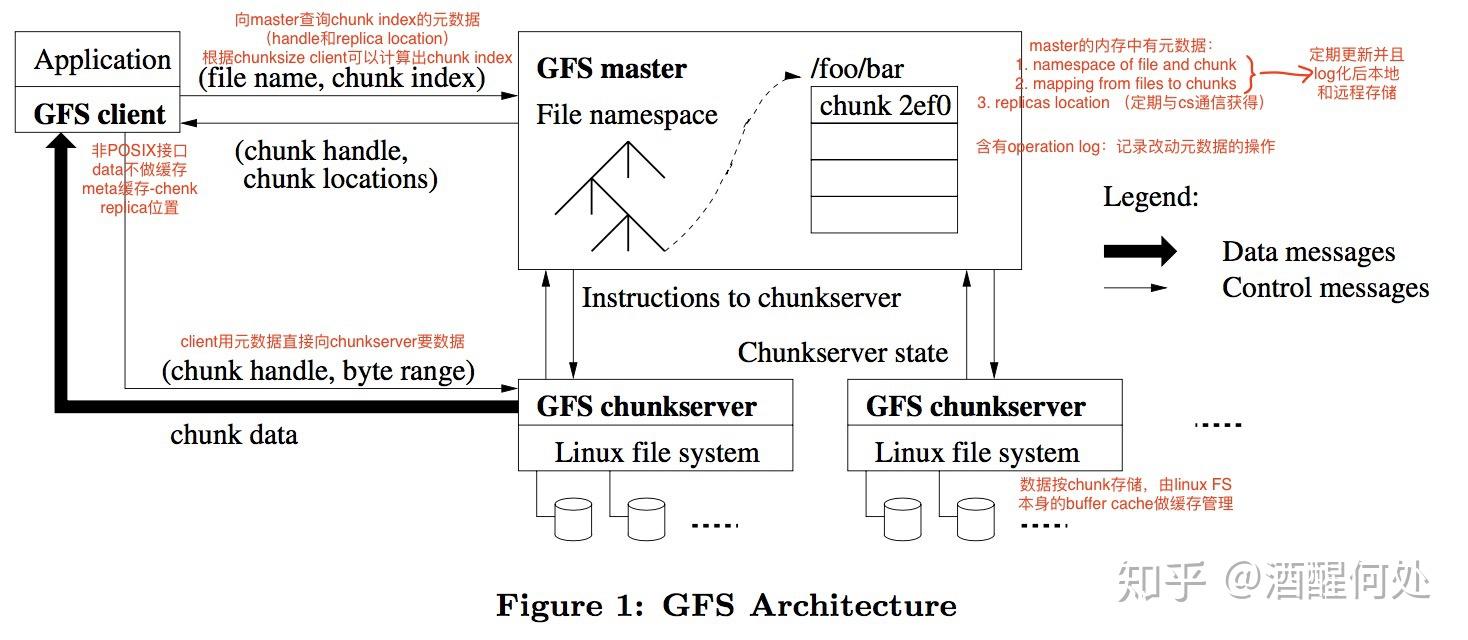
从架构图中可以看到,一个GFS集群包含一个Master节点、多个Chunk Server服务器、以及允许被多个Client客户端访问。所有的机器资源都是普通的Linux服务器,只要机器资源够用Chunk Server服务器和Client客户端都放在同一台服务器上。
存储文件时,GFS将文件分割成固定大小的Chunk,在Chunk创建时,Master服务器会给每个Chunk分配一个不变的、全球唯一的64位标识——Handle句柄,Chunk Server把Chunk以普通Linux文件的形式保存在本地硬盘上,并且根据指定的Handle句柄和字节范围来读写数据。为了避免节点异常带来的数据损坏,GFS把每个Chunk以副本Replica的方式冗余备份到不同的Chunk Server服务器上。默认使用3副本策略,用户可以为不同的文件命名空间设定不同的复制级别。
Master负责维护整个集群的元数据,包括集群的名字空间Namespace、访问控制信息、文件和Chunk的映射信息、当前Chunk的位置信息、Chunk Lease租约管理、Chunk回收、Chunk在服务器之间的迁移等系统级操作。Master节点通过心跳信息周期性地跟每一个Chunk Server服务器通信,发送指令到各个Chunk Server服务器,并接收各个Chunk Server服务器的状态信息。
Client客户端代码以库的形式被链接到客户程序中,客户端代码实现了GFS文件系统的API接口函数、应用程序与Master节点和Chunk Server服务器通信、以及对数据进行读写操作。Client客户端与Master节点的通信只是获取元数据,所有的数据操作都是Client客户端直接跟Chunk Server服务器进行交互的,如上图所示,数据流和控制流是分开的,这样就避免了Master节点成为性能瓶颈。
Client客户端和Chunk Server服务器都不需要缓存文件数据,Client客户端只需要缓存元数据,因为大部分文件要么以流的方式被读取,要么太大而无法缓存。而Chunk Server服务器本身就是以Linux文件的形式存储数据,其Linux内核的Page Cache页缓存会缓存文件数据的。
GFS的设计决策
从上面的架构图,我们可以看到Google设计的几个原则:简单原则、根据硬件特性做设计取舍、根据实际应用做设计取舍。
第一个,简单设计原则:
首要的简单是文件存储就是普通的Linux文件,充分利用了Linux特性。其次简单是单一的Master节点策略,这个就大大简化了设计,单Master让整个GFS的架构变得非常简单,避免了复杂的一致性问题。当然这也带来了很多限制,比如:一旦Master出现故障,整个集群就无法写入数据,而恢复Master就需要人工介入,从这一点来看,GFS Master节点并不是一个高可用的系统。那么怎么提高可用性呢?工程实现上有很多手段,GFS采用了Checkpoint、操作日志,引入影子节点Shadow Master等一系列手段,这再次印证了计算机技术实现上“扬长避短”的思想,发挥其长处,针对短处,采取一系列手段去优化弥补。
第二个,根据硬件特性做设计取舍:
首先,在GFS论文发表的年代,大家还在使用机械硬盘,对机械硬盘,我们都知道其随机读写的性能很差,所以GFS的设计中主要是顺序读写操作,以Append追加的方式写入数据,以流式访问读取数据。
其次,当时的数据中心,服务器的网卡带宽普遍是百兆网卡,网络带宽往往是系统的性能瓶颈,因此,GFS设计使用流水线式的数据传输机制。
第三,在文件复制操作时,GFS专门设计了一个Snapshot,其目的也是为了避免复制时数据在网络上传输。这些设计都是避免有限的网络带宽成为性能瓶颈。
第三个,根据实际应用做设计取舍:
GFS是为了在廉价硬件上做大规模数据处理而设计的,所以GFS的一致性相当宽松,GFS对随机写入的一致性没有任何保障,对于Append追加操作,GFS也只是做了“At Least Once”至少一次的保障。这个任务被交给了客户端,通过在客户端中实现校验、去重这样的处理机制,这样GFS在大规模数据处理上也可以很好适用。
下面我们根据这些设计原则进一步分析GFS的论文,第一个简单原则。GFS是单Master节点策略,非常简单,但是这个Master实际上有三种不同的身份,分别是:
- 如果从存储数据的Chunk Server来看,Master是一个目录服务。
- 如果从灾难恢复的Backup Master,Master是一个符合主从架构的同步复制的主节点。
- 如果从保障读数据的可用性而设计的Shadow Master,Master是一个符合主从架构的异步复制的主节点。
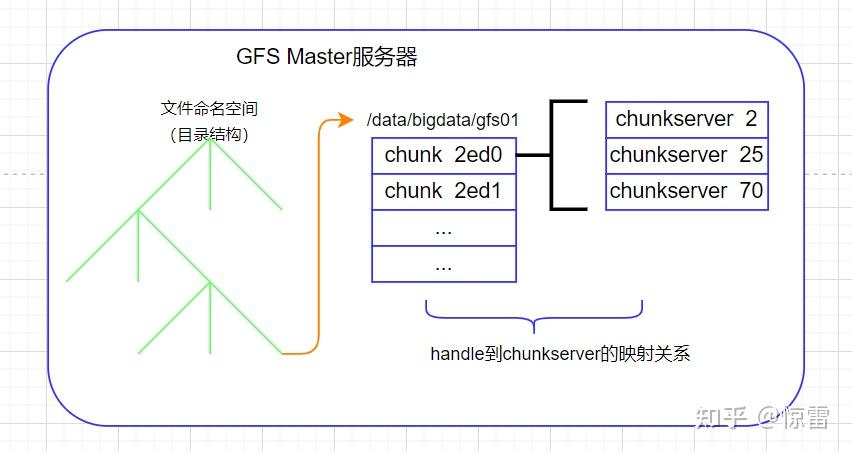
当我们要把一个文件存储在GFS上的时候,GFS会通过“命名空间+文件名”来定义一个文件,比如:/data/bigdata/gfs01,这样所有GFS的客户端都可以通过/data/bigdata/这个命名空间,加上文件名gfs01,去读写这个文件。这时就会有一个问题:读写的时候,这个文件到底存储在哪个服务器上呢?客户端具体是怎么读到这个文件的呢?
在GFS中有两种节点:Master和Chunk Server。Master有且只有一个主控节点,Chunk Server就是实际存储数据的节点,因为GFS是分布式文件系统,因此,文件是存储在不同的服务器上的。GFS把文件按照64MB一块的大小,切分成一个个的Chunk块,每个Chunk都会有一个在GFS上的唯一的handle句柄,这个handle句柄就是一个64位编号,能够唯一标识出一个Chunk,每个Chunk都会以文件的形式存放在Chunk Server上。而Chunk Server就是普通的Linux服务器,运行GFS的Chunk Server程序,它负责和Master以及Client进行RPC通信,完成实际的数据读写操作。为了确保数据的可靠性,不至于因为某个Chunk Server服务器挂掉就出现数据丢失,每个Chunk都会有3个副本,其中一份是主数据Primary,两份是副数据Secondary,当三份数据出现不一致时,就以主数据为准。副本技术不仅可以防止各种异常出现的数据丢失,还能在并发读取时,分担系统读压力。这样一来,文件就被拆分成了一个个的Chunk存在Chunk Server上,那么Client怎么知道去哪个Chunk Server上找自己要的文件呢?这就用到Master了。因此,我们看下Master中存储的元数据metadata信息:
- 文件和Chunk的命名空间信息,即:/data/bigdata/gfs01,这样的命名空间和文件名。
- 文件被拆分成了哪几个Chunk,即:命名空间文件名到多个Chunk Handle句柄的映射关系。
- 这些Chunk实际存储在了哪些Chunk Server上,即:Chunk Handle句柄到Chunk Server服务器的映射关系。
当客户端去读GFS里面的数据的时候,需要怎么做呢?
客户端先去问Master节点:我要读取的数据在哪里?客户端会把文件名和数据范围(offset和length)发送到Master上,因为文件被按照固定大小(64MB)切割成chunk了,所以很容易计算出要读取的数据在哪几个chunk里面,客户端就会告诉Master,我要读取哪个文件的第几个chunk。Master把这个chunk对应的所有副本所在的chunkserver告诉客户端,客户端拿到这个信息后,就可以去任意一个chunkserver上读取所需的数据。
其实整个过程本质上跟Linux文件系统差不多,核心思想都是一脉相承,Master节点就好比superblock和所有的inode,chunk就是文件系统中的block块,只不过尺寸大了些,且分布在不同的机器上。客户端通过Master节点读取数据的过程,就好比文件系统中通过inode查找block,然后从指定block读取数据的过程。所以这个时候的Master就是一个“目录服务”,Master节点自身并不存储数据,而是存储“目录”这样的元数据信息,这跟单机上文件系统的设计思想是一样的。
很多大型复杂的系统设计都是从最简单、最底层的技术和系统演化而来的,为了特定的功能或应用场景进行针对性的优化,扬长避短。再比如像数据结构和算法中的数组和指针,由二者演化出很多的复杂数据结构和算法,由数组的二分查找演化出链表的二分查找(跳表)。下面我们来看简单的长处背后是如何避短的:Master节点的容错性和可用性保障。
Master简单的背后是有代价的,我们能看到,在这个设计中,Master节点压力很大,很容易成为性能瓶颈,如果几百个客户端并发读取数据,都要去Master上找,这就要求Master节点把所有的数据都存储在内存中,这样Master的性能才能跟得上,但是数据放在内存中问题也很明显,一旦Master节点重启或挂掉,内存中的数据就丢失了,怎么办?通过记录操作日志和定期生成对应的Checkpoint进行持久化,也就是存储到磁盘上,这样就不怕内存因故障而数据丢失了。当Master重启时,就先读取最新的Checkpoint,然后进行回放(replay)操作日志,这样就可以让Master节点恢复到之前最新的状态,这就是存储系统常用的可恢复机制。
仅仅能恢复内存数据也不靠谱,如果Master节点机器故障无法恢复呢?这个时候就要考虑准备“备胎”了。比如:增加 Backup Master,所有针对Master的操作都同时写入Backup Master上,只有Master上操作成功且写入磁盘成功,还有Backup Master上也操作成功且写入磁盘成功,整个操作才视为成功。这种方式叫做 同步复制,是分布式数据系统中一种典型的模式。比如在Mysql中也经常这样使用,高可用的Mysql一般都是主从架构的同步复制模式。当Master节点故障后,Backup Master节点便会转正,变成新的Master,而里面的数据都是一摸一样的。那么怎么能检测到Master挂掉呢?这就需要一个监控程序,监控Master服务的运行状态,如果只是master服务挂了,只要重启master服务;如果是Master节点故障,就选择一个Backup Master节点成为新Master。为了让集群中其他Chunk Server和客户端不用感知这个Master切换的变化,GFS通过一个规范名字(Canonical Name)来访问Master节点,这类似于DNS别名,这样,一旦要切换Master,这个监控程序只需要修改别名实际指向,访问新的Master节点就能达到目的。有了这个机制,GFS的Master就可快速恢复(Fast Recovery)。
尽管如此,对于几百个客户端访问的GFS,仍然面临在故障恢复过程中无法读取的问题,这个该怎么解决呢?办法就是加入一些 只读的影子节点Shadow Master,这些Shadow Master节点不同于Backup Master节点,Master写入数据并不需要等待这些Shadow Master节点也写入成功,而是这些Shadow Master节点不断地从Master节点上同步数据,这种方式叫做 异步复制,是分布式数据系统中另一种典型的模式。在异步复制模式下,这些Shadow Master节点上的数据跟Master节点上的数据并不是完全同步的,而是可能有小小的延迟。这可能导致这些Shadow Master节点上元数据信息不是最新的,但实际上,这种情况发生的概率还是很小的,因为这需要同时满足三个条件:
- Master节点挂掉
- Shadow Master节点没有同步完最新的操作日志和Checkpoints
- 恰好要读取的那部分数据就是没有同步完的部分
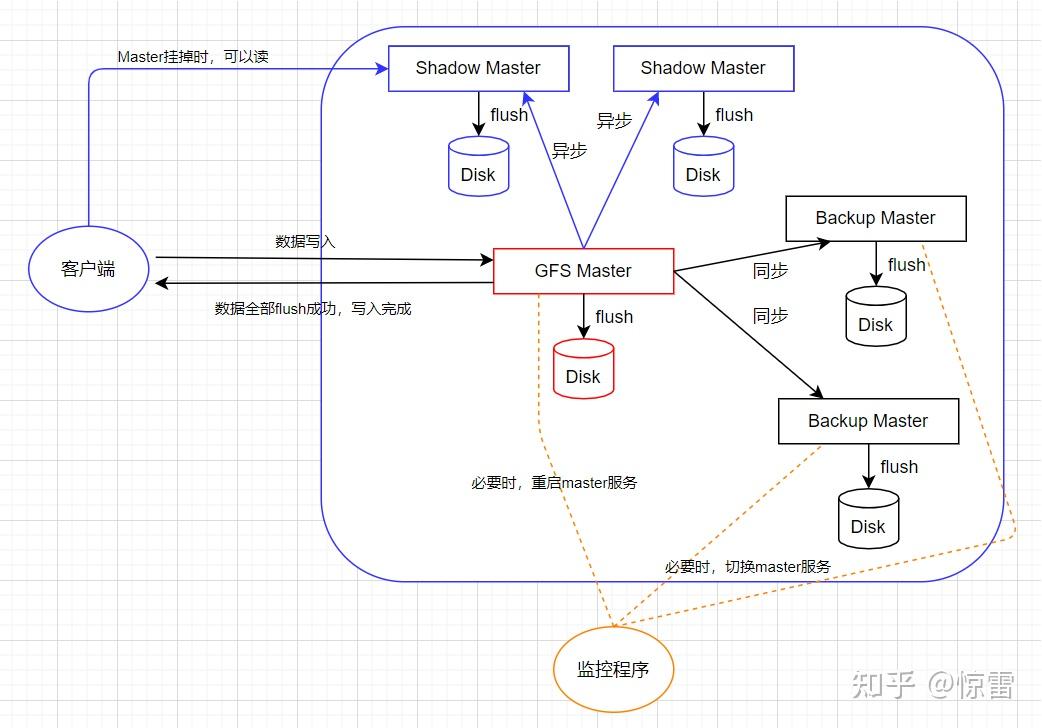
实际上,Shadow Master为了保持自身状态是最新的,他会读取一份当前正在进行的操作日志副本,并依照跟Master完全相同的顺序更新内部数据。Shadow Master在启动时也会从Chunk Server服务器上轮询数据(之后定期拉数据),数据包括副本的位置信息。Shadow Master也会定期和Chunk Server服务器“握手”来确定他们的状态,只有在Master节点因为创建和删除副本导致副本的位置信息变化时,Shadow Master才和Master通信更新自身状态。通过Backup Master和Shadow Master,GFS构建了高可用(HA)架构。
GFS根据硬件特性做设计
软件系统的设计跟其他物品的设计是一样的,它不是抽象的存在于纸上,还需要考虑真实的物理硬件性能和限制条件,GFS就是典型,它充分考虑了硬件特性来做设计的取舍。什么硬件?又有哪些特性限制?
GFS是基于廉价计算机硬件来设计的,我们知道单台机器性能瓶颈通常是硬盘,大数据系统是为海量数据而设计的,也必然要追求高性能,单台机器有硬盘的性能瓶颈,那就搭建成百上千台服务器,通过网络组成一个大数据集群,这个时候我们发现网络也会成为新的性能瓶颈。
我们先来看GFS的数据写入过程:
- 客户端会去问Master要写入的数据应该在哪些ChunkServer上。
- Master会告诉客户端数据可以写入的副本位置信息,还要告诉客户端哪个是主副本Primary Replica,数据此时以主副本Primary Replica为准。
- 客户端拿到副本位置信息后,即:应该写入哪些ChunkServer里,客户端会把要写入的数据发送给所有副本。此时ChunkServer把接收到的数据放在一个LRU缓存中,并不真正地写数据。
- 等所有次副本Secondary Replica都接收完数据后,客户端就会给主副本Primary Replica发送一个写请求。因为客户端有成百上千个,会产生并发的写请求,因此主副本Primary Replica有可能收到很多客户端的写请求,主副本Primary Replica会将这些写请求排序,确保所有数据的写入是按照一个固定的顺序。主副本Primary Replica将LRU缓存中的数据写入实际的Chunk里。
- 主副本Primary Replica把写请求发送给所有的次副本Secondary Replica,次副本Secondary Replica会和主副本Primary Replica以同样的数据写入顺序,将数据写入磁盘。
- 次副本Secondary Replica数据写完后,将回复主副本Primary Replica写入完毕。
- 主副本Primary Replica再去告诉客户端,这次数据写入成功了。如果有某个副本写入失败,也会告诉客户端,本次数据写入失败了。
由上面的数据写入过程可知,因为数据是写入到不同的ChunkServer上,这就会出现部分写入成功,部分写入失败的情况,这就涉及到数据的一致性问题,这个我们在“根据应用做设计取舍”里再分析,这里我们集中分析“根据硬件特性做设计”,怎么体现的这一点呢?我们看数据的复制流程:
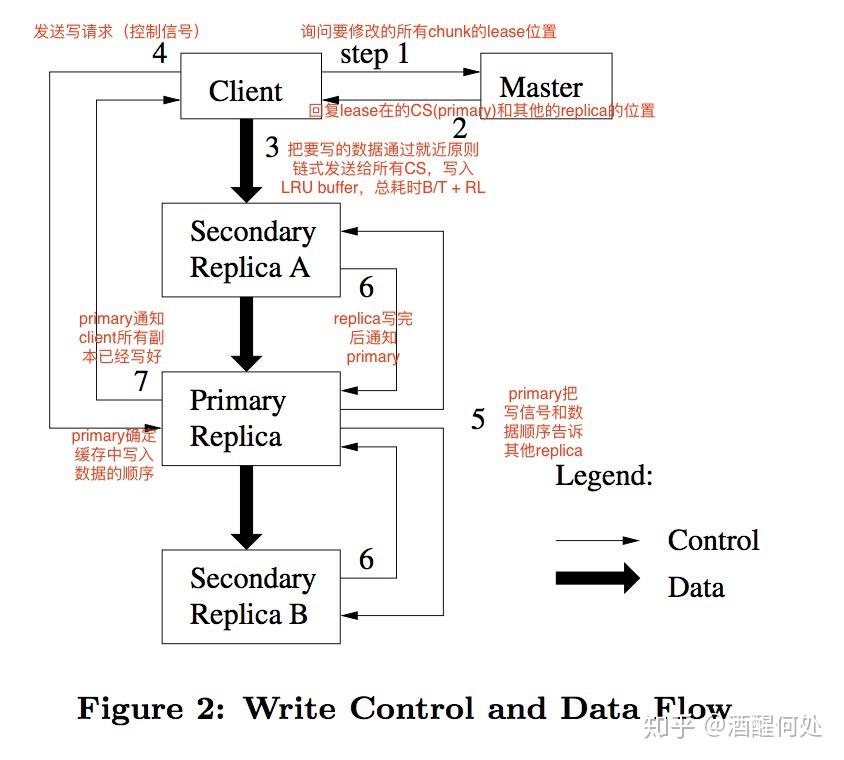
从这张设计图中,我们看到控制流和数据流是分开的,数据流的复制过程是流水线式的。为什么要这么设计?
先来看控制流和数据流的分离:客户端只是从Master节点上拿到了数据应该写入哪些ChunkServer,而实际的数据传输并不经过Master节点,多个副本在ChunkServer上的协调写入过程也不经过Master节点。这就意味着提供指令的动作跟数据的传输和写入是完全分开的,这就使得Master节点不会承受太多的负载,避免Master节点成为性能瓶颈。
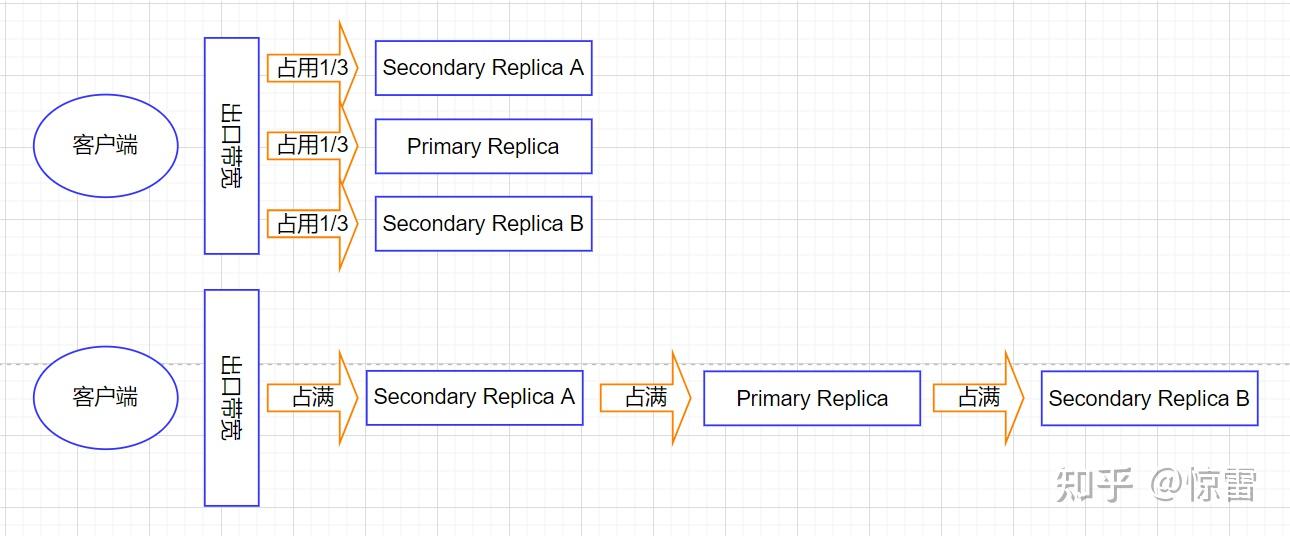
前面硬件分析时已说过,网络可能成为最大的瓶颈,如果用最直观的方法,即:客户端把数据直接发给所有ChunkServer,客户端的出口网络会立刻成为性能瓶颈。比如:1GB的数据,客户端的出口带宽为100MB/s,那么数据需要10s就能发送完,由于客户端需要同时发送给三个ChunkServer,这就需要30s才能发送完,而每个ChunkServer的入口带宽也并没有充分的利用起来。那要怎么设计才能充分利用硬件特性,避免网络瓶颈呢?既然同时发送给三个ChunkServer不好,那就一个一个的发,如果只是让客户端一个一个的发,似乎还未收到数据的ChunkServer就只能被动等待,有没有更好的方式?福特发明的流水线车间大幅提高了生产效率,一端送进原材料,另一端就源源不断的生产出汽车来,把这种流水线模式引入数据传输同样提高了数据传输的效率。
流水线(pipeline)式的网络数据传输
数据不一定是先给到主副本,而是看网络中离哪个ChunkServer更近,就给那个最近的ChunkServer,如上图所示,客户端先把数据传输到离自己网络最近的次副本Secondary Replica A上,而且次副本Secondary Replica A是一边接收客户端发来的数据,一边又把数据发送给离自己最近的主副本Primary Replica上,同理,主副本Primary Replica也是一边接收次副本Secondary Replica A发来的数据,一边又把数据发送给离自己最近的次副本Secondary Replica B,这就是流水线式的数据传输方式。这样只要网络上没有拥塞情况,只需要10s多一点,就可以把数据从客户端传递给三个副本所在的ChunkServer服务器上。流水线式的数据传输方式可以有效利用满客户端和ChunkServer的网络带宽:
这里有个问题:为什么要强调客户端 ”先把数据传输到离自己网络最近的次副本Secondary Replica A上”,而不是直接发送给主副本Primary Replica呢?我们看下这张传统三层交换的数据中心网络拓扑图就明白了。
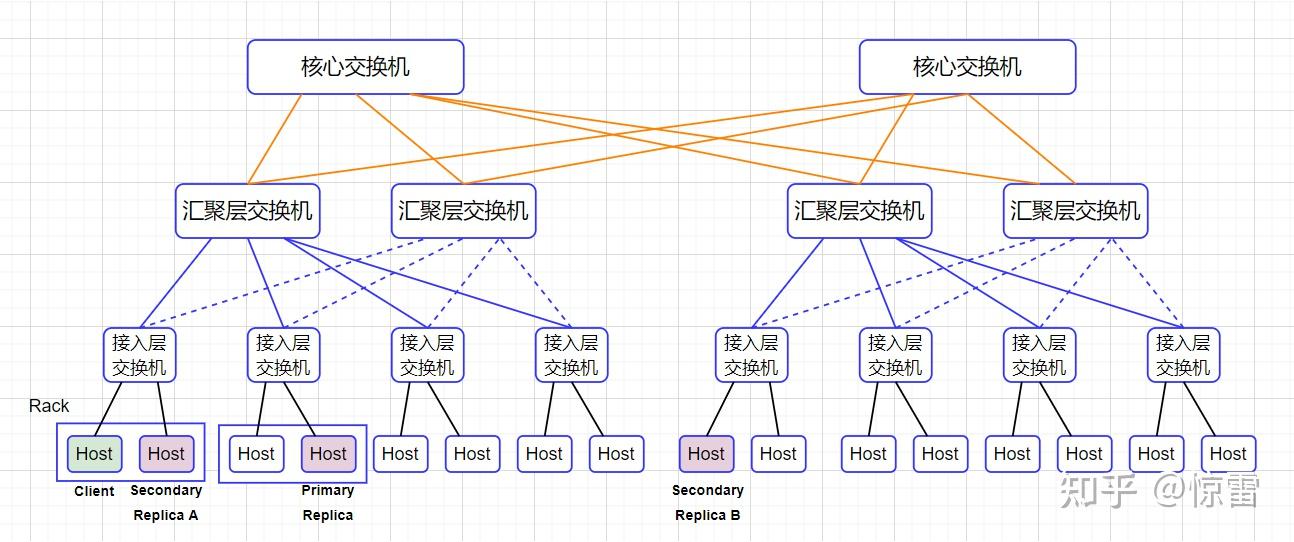
如上图所示,数据中心有几百台服务器,通过三层网络连接起来:
- 同一个机架Rack上的服务器都会接入一台接入层交换机(Access Switch);
- 各个机架上的接入层交换机都会连接到一台汇聚层交换机(Aggregation Switch);
- 汇聚层交换机会再连接到核心交换机(Core Switch);
由此构成一个三层网络拓扑图,这样你就会发现:如果两台服务器在同一个机架Rack上,它们之间的网络传输只需要经过接入层交换机,即:除了两台服务器自身的网络带宽外,只会占用所在的接入层交换机的带宽。如果不在同一个机架上,甚至不在同一个VLAN内,就需要通过汇聚层交换机,甚至核心交换机,这个时候汇聚层交换机或核心交换机就有可能成为性能瓶颈。
这样我们再来看流水线式的数据传输过程,就明白GFS为何这样设计,既充分利用了网络带宽,又减少了交换机的网络瓶颈。
除了上面的两点外,我们再来看GFS还有哪些优化的设计?GFS为常见的文件复制操作设计了一个单独的指令:文件复制Snapshot操作。
复制文件我们通常会怎么做呢?读一个文件,然后重新写一份,在GFS分布式文件系统中,读数据要经过网络传输,写数据又要经过网络传输,这样做貌似也可以,但是这是不是最优解呢?GFS为文件复制单独设计了一条Snapshot指令,客户端通过这条指令复制文件时,指令会通过控制流下发到主副本Primary Replica,主副本Primary Replica再下达到次副本Secondary Replica,然后各个副本所在的ChunkServer直接在本地复制一份对应的Chunk数据,这就避免了来回的网络传输问题。
一致性问题
前面我们已分析GFS的写操作,3副本的情况下,同一份数据要写入不同的ChunkServer服务器,这必然会有部分写入成功,部分写入失败的问题,这就是数据写入的一致性问题。一致性就是CAP理论中的Consistent,在GFS中,一致性具体什么含义?论文中是这样定义的:

数据的修改分为:写入Write和记录追加Record Append。其结果有:顺序写入成功Serial success、并发写入成功Concurrent successes、写入失败。两种写入方式,三种写入结果,那么数据就会有不同的状态,GFS使用“确定的defined”和“一致的consistent”在标识数据的状态。怎么理解呢?
一致的consistent:就是客户端无论从主副本Primary Replica读数据,还是从次副本Secondary Replica读数据,读到的数据都是一样的。即:多个副本Replica读出来的数据是一样的。
确定的defined:就是客户端写入的数据能够完整地被读到。即:每个客户端写入指定offset的数据 和 再从offset读出来的数据是相同的。
这就是GFS定义的数据一致性问题,首先,如果数据写入是失败的(部分副本成功,部分副本失败也是写入失败),那么GFS中的数据必然是不一致的inconsistent。这个很好理解,GFS的数据写入并不是一个事务,前面已述,客户端发送写入指令给主副本Primary Replica,主副本Primary Replica再下发指令到次副本Secondary Replica,如果主副本Primary Replica和其中部分次副本Secondary Replica写入成功了,而部分次副本Secondary Replica写入失败,那么客户端读取到的数据就是不一致的。
其次,如果是顺序写入,写入成功,那么文件中的数据就是确定的defined,客户端读到的数据也是确定的defined。客户端写入数据需要指定offset,数据写入的位置和大小是已知的,比如:客户端A和客户端B分别写入数据,因为是顺序写入的,客户端A写Chunk成功,客户端A从offset处读上来的就是A的数据,这是确定的;同理,客户端B也写Chunk成功,客户端B从offset处读上来的就是B的数据,这也是确定的。这种情况下的数据写入就是确定的defined,也就是说,客户端A写入的数据就是客户端A的数据,这次写操作成功后,其数据就是确定的,无疑的,不会出现不确定的情况。即便客户端B后来也写入了同样的位置,那是客户端B的写操作,客户端B写成功后,它的数据也是确定的、无疑的,不会出现不确定的情况。
如果是并发写入成功呢?由于多个客户端并发地向同一个文件中写入数据,三副本都写入成功了,如果多个客户端写入的数据有可能出现交叉,比如客户端A写入数据范围[50, 80],客户端B写入数据范围[70, 100],就会出现下面的情况:客户端A写入成功后,客户端B有可能会覆盖了客户端A的数据;也可能是客户端B写入成功后,客户端A可能覆盖了客户端B的数据。但是客户端A和客户端B都写成功了,其3个副本都是按同样的顺序写的数据,客户端无论从哪个副本读,数据都是一致的consistent,但是客户端去读自己写入的数据,就会出现读出来的数据有部分交叉的内容,这部分内容是客户端A写入的,还是客户端B写入的是不确定的undefined。
所以并发写入成功时,这种情况文件数据就是一致的但是不确定的consistent but undefined状态。为什么会出现这种情况?一是,数据的写入顺序并不需要通过Master来协调,而是直接发送给ChunkServer,由ChunkServer来管理数据的写入顺序;二是,随机写操作大概率会横跨多个Chunk。这就导致一个Chunk可能既包含数据A,又包含数据B。随机数据的写入并非原子性的,也没有事务性保证,因此需要客户端在写入数据时是顺序写入的,避免并发写入的出现。那么问题也来了,GFS允许几百个客户端读写访问,那该怎么避免这种一致但非确定的状态呢?GFS设计了记录追加Record Append来解决这个问题。
记录追加Record Append的“至少一次”的保障
我们希望是什么样呢?并发写入的数据是确定的defined,客户端A写入的数据就是客户端A的,不会被客户端B覆盖掉,客户端B写入的数据就是客户端B的,不会被客户端A覆盖掉,这就要求保障写入是原子性的。看看GFS到底是怎么做的:写操作时,GFS并不指定在Chunk的哪个位置offset写入数据,而是告诉Chunk的主副本Primary Replica服务器“我要追加记录”,由主副本ChunkServer根据当前Chunk位置决定写入的offset,在写入成功后将该offset返回给客户端,客户端根据offset确切知道写入结果,无论是串行写入,还是并发写入,其结果都是确定的defined。
具体的处理流程:
- 首先,主副本ChunkServer会校验当前的Chunk能否容纳下要追加的数据,如果能,主副本ChunkServer就将数据追加到当前Chunk中,然后给次副本ChunkServer发送指令,次副本ChunkServer也将数据追加到副本Chunk中。
- 如果当前的Chunk不能容纳,主副本ChunkServer就把当前Chunk剩余空间填充空数据,然后发送给次副本ChunkServer也把副本Chunk剩余空间填充空数据;然后主副本ChunkServer回复客户端“在下一个Chunk上写入”,客户端重新从Master节点获取新的Chunk位置,数据传输完毕后,再次向新的Chunk所在的主副本ChunkServer发起写指令。
- 因为数据写入的顺序是由主副本来控制的,且数据写入只有追加操作,因此主副本ChunkServer会将并发写入的数据进行排队,然后依次追加写入,这样就不会出现相互覆盖的情况了。
- 为了确保Chunk剩下的空间能存的下需要追加的数据,GFS限制了一次记录追加的数据大小为16MB,而Chunk大小默认是64MB,所以当空间不足需要补空数据时,最多也就是16MB,也就是最多也就浪费1/4的空间,不至于浪费太多。
那么“defined interspersed with inconsistent确定的但夹杂着不一致的数据”该怎么理解呢?我们看两个例子:
例子1:无并发的记录追加
客户端追加了一个数据a,第一次执行一半Secondary2失败了,那么此时这个Chunk的副本情况如下:
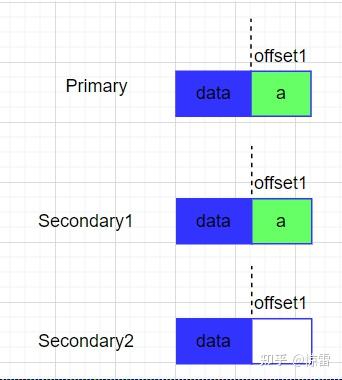
于是,客户端重新发起一次追加写操作,Primary先操作offset2后再将请求发给Secondary操作offset2,由于Secondary2上次操作offset1未成功,所以会先补空数据,然后再从offset2处写数据,那么此时副本情况如下:

例子2:并发记录追加
两个客户端分别向同一个文件追加数据a和数据b,Client1追加数据a,Client2追加数据b。假如Primary排序b,a。然后执行追加写操作,假如执行一半Secondary2失败了,同理,Client2会再次追加一遍,那么这个Chunk的副本情况如下:
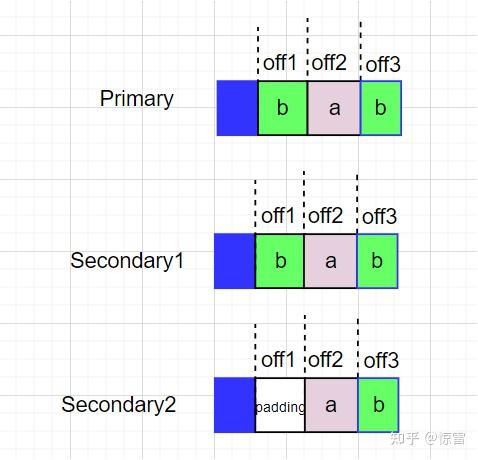
于是Client1收到offset2,Client2收到offset3,offset2和offset3都是确定的defined,而offset1是不一致的inconsistent,同样是“defined interspersed with inconsistent确定的但夹杂着不一致的数据”。
不同的副本中可能被追加了不同的次数,但“至少一次”是确定的defined,这就是“At Least Once”,这就是GFS承若的一致性。可见GFS对写入数据的一致性保障相当低,它只是保障了所有数据追加至少被写入一次。不过,这其实很符合Google的实际应用情况,因为Google作为搜索引擎是不断抓取网页存到GFS上,其实并不在意被重复存储了几次。对于数据写入失败带来的部分数据不完整问题,GFS在客户端自带了对写入的数据去添加校验和(checksum),在读取数据的时候计算验证数据的完整性功能。而对于重复写入多次的问题,也可以对每一条要写入的数据生成一个唯一的ID,带上时间戳,那么即便数据顺序不对,有重复,也很容易在数据处理中根据ID进行排序和去重。
这就是,根据实际应用做设计取舍。这样的设计——“至少一次”,带来了很大的好处:一是,高并发和高性能,因为只涉及到追加Append操作,对于机械硬盘来说效率最高,性能最好,又满足多客户端并发操作;二是,简单,单一的Master设计,Master只负责控制协调,不需要复杂的一致性算法。而且在当年只有晦涩难懂的Paxos,还没有相对简单的Raft算法出现,现如今Raft算法已经是数据一致性问题使用最广泛的解决方案。